 大人問小孩: 「全世界的玩具隨便你挑? 這怎麼可能?
如果我要的玩具只有一個, 正好又被別人借走了呢?」
大人問小孩: 「全世界的玩具隨便你挑? 這怎麼可能?
如果我要的玩具只有一個, 正好又被別人借走了呢?」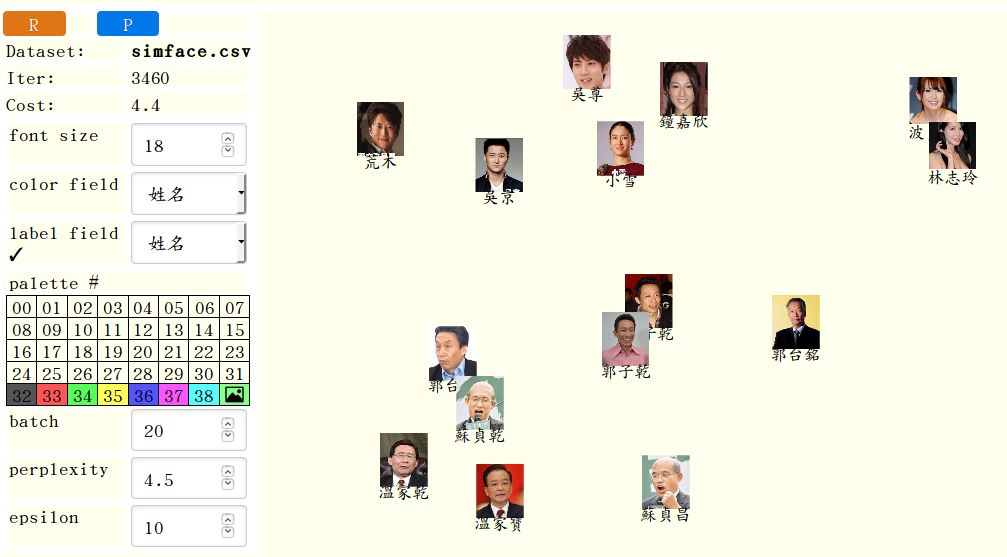 覺得你自己或家人/朋友跟某名人長得很像嗎?
還是覺得身旁的誰跟誰撞臉呢?
讓 AI 來對你的照片發表它的意見吧! 快先到
測試網頁 玩一下囉!
注意: 按了紅色的 R, 等了一陣子圖片大致就定位之後,
記得要按藍色的 P 停止運算!
不然它會一直浪費你的 CPU。
覺得你自己或家人/朋友跟某名人長得很像嗎?
還是覺得身旁的誰跟誰撞臉呢?
讓 AI 來對你的照片發表它的意見吧! 快先到
測試網頁 玩一下囉!
注意: 按了紅色的 R, 等了一陣子圖片大致就定位之後,
記得要按藍色的 P 停止運算!
不然它會一直浪費你的 CPU。
一、 t-sne-lab 圖片功能展示
t-sne-lab 的操作, 以及如何離線使用, 詳見 t-SNE 幫你看見高維度數值資料。 寫完那篇之後, 我又加了圖片功能 -- 如果你的資料裡面有一欄是圖片檔的 (部分) 名稱, 那麼可以在設定檔 (*.json) 裡面用 "pic" 欄位指定:
- "colName": 哪個欄位存放圖片檔的 (部分) 名稱
- "prefix": 在每個圖片檔名之前, 全都加上某個字串。 (例如若是子目錄的名稱, 要以 "/" 結尾!) 又, (就像 .json 設定檔一樣) 這裡其實也可以放 url; 不過那就失去 t-sne-lab 離線執行保護隱私的目的了。
- "suffix": 在每個圖片檔名之後, 全都加上某個字串。 (例如 ".jpg" 或 ".png")
- "width": 圖片顯示的寬度
- "height": 圖片顯示的高度
建議所有圖片的 aspect ratio (長寬比) 最好相同, 才不會有些圖片變形。 一旦設定了 pic 欄位, t-sne-lab 就會自動直接顯示圖片。 但你也可以點選 palette 的其他格子, 改用圓點取代圖片。 若要切換回圖片, 就點 palette 最右下角那一格風景圖示。
這些圖片的出處包含: 明星撞臉、 无性别脸孔、 這噗 還有許多搜尋結果。
心動了嗎? 想要玩自己的相片, 有兩條路可走。 (1) 直接在你的 linux 上面安裝。 (2) 採用專為機器學習所打包的 docker。 因為我們要用的 「基于Python的开源人脸识别库」 face_recognition 的相依套件很多, 所以我自己是採用偷懶的 (2)。
二、 在 floydhub/dl-docker 裡面試用 face_recognition
- 先照著做: 很犯規的 caffe 初體驗 第一節 「準備 floydhub/dl-docker」。
pip install face_recognition
注意 1: 目前 floydhub/dl-docker 的版本是 ubuntu 14.04
(見 cat /etc/os-release) 我用 pip 指令而非 pip3,
因為用 python2.7 編譯比較簡單。
注意 2: 在較慢的電腦上, 安裝 face_recognition 要花一二十分鐘,
主要是編譯 dlib 要很久。
如果等一下執行 face_recognition 指令時出現 「Illegal instruction (core dumped)」 這樣的錯誤, 那表示你的 CPU 太舊, 少了某些指令。 這時必須重新編譯、 重新安裝 dlib:
pip uninstall dlib pip download dlib tar xzf dlib*.tar.gz cd dlib-版本 nano tools/python/CMakeLists.txt # 把 set(USE_SSE4_INSTRUCTIONS ON CACHE BOOL "Use SSE4 instructions") # 那一句的兩個 SSE4 都改成 SSE2。 存檔離開 nano pip install --no-clean .
如果沒耐心、 衝動之下按下了 ctrl-c, 建議把整個目錄砍掉, 從解壓縮開始重做, 以免新舊檔案混雜。 又, 我的電腦超級舊, 連 SSE2 指令都沒有, 所以乾脆直接把整句 set() 刪掉、 重編, 就 ok 了。
以上是最困難、 最可能遇到問題的部分。 再來就只是整理資料跟下指令而已。
把
t-sne-lab 抓回去, 放在 host 跟 docker 共用的目錄裡。
其中的 simface.csv 就是由 face_recognition 所產生、
餵給 t-sne-lab 吃的試算表檔案。 我們先看手工寫的部分,
也就是前兩欄: grep -Po '^[^,]*,[^,]*' simface.csv
第一欄是 jpg 檔名 (扣除副檔名); 第二欄是中文姓名。
乾哥的模仿照通通取名為 「XX乾」。
(謎之音: 還好乾哥沒有模仿 「朱若X」 之類名人)
在 t-sne-lab 底下, 建一個 unknown 子目錄,
並且把乾哥的一張照片搬過去, 像這樣:
mkdir unknown mv simface/kzc1.jpg unknown/ face_recognition simface/ unknown/
在很慢的電腦上要等幾秒鐘, 然後它會印出一串 unknown/kzc1.jpg,kzc-wjb 之類的字串, 表示 kzc1.jpg 看起來像是溫家乾、郭台銘、...等人。 (就說吧! 乾哥不必化妝就已經很像郭董了, 比自己還像!)
三、 幫你的相片產生 encoding
如果只是要玩人臉辨識, 可以直接拿原作者的程式。
如果想要產生試算表檔餵給 t-sne-lab 吃, 那就要下載我的
agface.py。 把它放在共享目錄下, 變成可執行檔
chmod a+x agface.py。 又假設你已把相片放在共用目錄裡的
t-sne-lab/ 底下的 fff/ (family and friend faces)。 在 docker 裡面
cd 進入 fff/ 子目錄, 執行:
/root/shared/agface.py encoding *.jpg > fff.csv
(假設在 docker 裡面看到的共用目錄是 /root/shared)
這就產生了一個 129 個欄位的試算表檔 fff.csv,
包含一個文字欄位 (檔名) 跟 128 個數字欄位。
這 128 個數字欄位 (應該吧, 我猜) 是人臉辨識類神經網路輸出之前的那一層。
也就是說, 一張臉的特徵大約可由這 128 個數字來描述,
稱為這張臉的 encoding。
四、 用 t-sne-lab 開啟你的 fff.json
請先按照 t-SNE 幫你看見高維度數值資料 的說明, 在你的瀏覽器裡試玩 file:///.../t-sne-lab/t-sne-lab.html?config=simface.json 接下來我們只需要按照 simface* 產生對應的檔案跟目錄就可以了。
先用 libreoffice 打開上一節產生的 fff.csv, 在檔名欄後面、 第一個數字欄之前, 加上一個空欄, 幫每張相片在這個新欄位填上姓名。 把檔名後面所有的 .jpg 去掉。 存檔。 再用 nano 或 geany 或 vim 把我的 simface.csv 的第一列剪貼到 fff.csv 的第一列去。 再用 libreoffice 打開 fff.csv 檢查看看試算表是否方方正正整整齊齊。 如果資料有誤, 到時在 t-sne-lab 裡面會看不到任何資料, 但也不會顯示任何錯誤訊息, 必須要按 ctrl-shift-k (firefox) 或 ctrl-shift-i (chrome) 才能 打開 javascript console 來除錯, 有點麻煩。
再把我的 simface.json 複製成 fff.json、 修改裡面的路徑。 改好之後, 把瀏覽器上網址最後的 simface.json 改成你的 fff.json, 重新整理頁面, 在畫面正中央出現一張照片 (其他都壓在底下), 大功告成!
接下來就是調整參數的問題。 最重要的參數是 perlplexity。 根據 發明人的說法, 正常的值介於 5-50 之間。 但考量幾個因素:
- 我的資料量很小
- 撞臉通常只有兩個人, 最多三個人在撞
- 這裡特意挑好多張乾哥的相片
最後我發現 3 到 5 之間的值效果比較好 (注意! perplexity 其實不必是整數, 小數也 ok。) 如果調成 2, 乾哥組會變成一直線。 如果調成 5 的話, 乾哥跟他的分身們就會對得更好; 但撞臉組就比較難分難捨。
另外, 本來我還放入羅志祥本尊跟女版羅志祥, 但結果整體的效果就變得很差。 可能是刪掉之後, 資料變成很明顯的三組, t-sne 算的結果比較好。
還有, 用 agface.py 產生 simface.csv 這個動作, 產生出來的值每次可能略有小差異。 如果效果不佳, 也可以試著重產生一次看看。
五、 心得與雜記
會開始玩這個, 是因為從 davecode 的噗看到 「基于Python的开源人脸识别库」 那篇文章。 向愛玩技術的朋友們大推 davecode 的噗!
agface.py 也可以拿來偵測人臉範圍, 像這樣:
./agface.py range *.jpg
它的輸出一樣可以餵給 rect2im 變成 ImageMagick 的指令。
不過如果只是要偵測人臉範圍,
用 facedetect 比較簡單。
另外, ./agface.py features *.jpg
則會把眉毛、眼睛、鼻樑、嘴唇等等部位的範圍標示出來,
變成一個 json 檔。 你可以用
jq 瑞士刀 挑出你要的部分, 再做其他處理。
一開始我是拿 labeled faces in the wild 資料集來玩。 不過身為欠缺世界觀的島國小民, 不認得幾位, 很沒感覺 :-(
化妝師很厲害; 不過乾哥更厲害! 如果 AI 看得見乾哥跟模仿對象的談吐神韻, 應該會更準吧。 乾哥受我一拜!


沒有留言:
張貼留言
因為垃圾留言太多,現在改為審核後才發佈,請耐心等候一兩天。