 大人問小孩: 「全世界的玩具隨便你挑? 這怎麼可能?
如果我要的玩具只有一個, 正好又被別人借走了呢?」
大人問小孩: 「全世界的玩具隨便你挑? 這怎麼可能?
如果我要的玩具只有一個, 正好又被別人借走了呢?」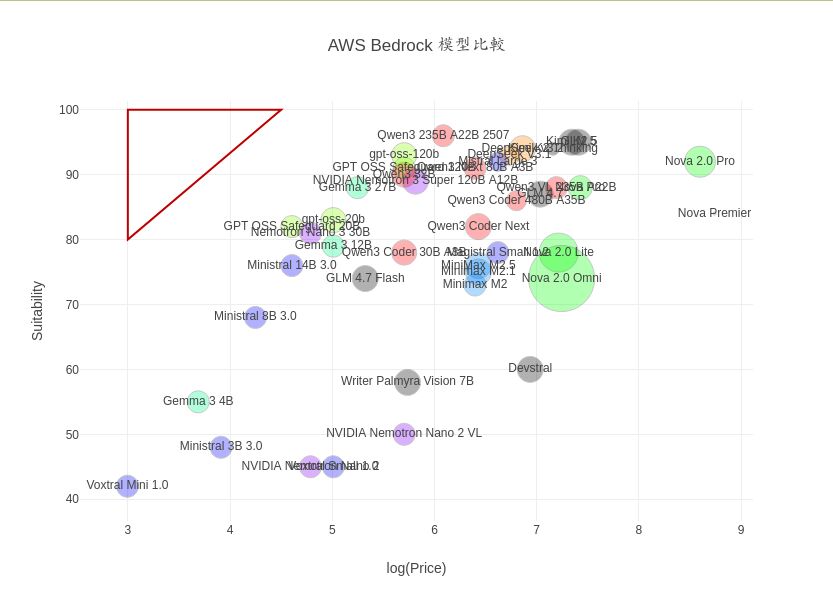 你挑了一個 LLM 租賃服務, 它提供很多模型。 該怎麼選?
我就拿 aws 的 bedrock 為例來解說資料視覺化 (散點圖/氣泡圖)
如何幫我們挑選性價比最佳的 LLM。
這些步驟應該也大致適用於比較整理其他 (來自同一家) 供應商的模型清單 -
只要你可以先建立一個 csv 檔列出該廠商提供的所有選項,
類似
我為 bedrock 建立的 bedrock-pricing.csv。
你挑了一個 LLM 租賃服務, 它提供很多模型。 該怎麼選?
我就拿 aws 的 bedrock 為例來解說資料視覺化 (散點圖/氣泡圖)
如何幫我們挑選性價比最佳的 LLM。
這些步驟應該也大致適用於比較整理其他 (來自同一家) 供應商的模型清單 -
只要你可以先建立一個 csv 檔列出該廠商提供的所有選項,
類似
我為 bedrock 建立的 bedrock-pricing.csv。
2026年5月3日 星期日
氣泡圖挑選性價比最佳的租賃 LLM
2026年4月25日 星期六
把買 GPU 的錢省下來租雲端服務: 建立 aws bedrock 模型與價格清單
想玩龍蝦 🦞、 不想買 GPU => 租雲端的 LLM 來用。 Amazon 有 aws bedrock。 他們家並沒有特別便宜, 但因為我有 aws 的點數, 那就拿來用吧! 請參考: 給小白的 bedrock 簡介、 bedrock 網頁介面試用心得。 不過, 我喜歡下指令, 所以是在 debian 上面安裝 awscli 套件來測試。 假設你已經 用 aws configure 命令設定好 access key, 也略微熟悉 jq。 我們的目的只是要跟 OpenClaw 接軌, 所以只關心有哪些模型可選擇、 如何下簡單的呼叫指令, 以及價格。
2026年4月24日 星期五
ollama 雜記: 模型檔案位置與大小
想在自己的電腦離線跑AI, 就要安裝模型管理器 ollama。 Ollama 安裝、模型比較、硬體需求與工具整合 之類的中文教學資訊已經很豐富。 我這裡只補充記錄一點沒那麼容易找到的資訊。
在 linux 底下, 安裝完成之後, 用 ollama pull ...
下載回來的模型的相關檔案都放在這裡:
/usr/share/ollama/.ollama/models/ 。
其下有兩個子目錄: blobs/ 底下是真正的模型檔 (佔很大的空間);
manifests/registry.ollama.ai/library/ 子目錄底下則是元資料,
就是描述每個模型的資訊。
2025年9月11日 星期四
NotebookLM: 「太長太多了,讀不完」 的好幫手
某個主題的文件 TL;DR (太長太多了,讀不完) 嗎? 那就讓 NotebookLM (<==請先讀簡介文) 來幫忙吧! 這裡分享我的一個粗淺心得範例: 微軟強推 edge , 採用了哪些暗黑模式?
[2026/1/4] 看起來,日常生活多數時候, gem 製作的「懶人媒體識讀助理」 就夠了。 NotebookLM 比較適合「聚焦一個主題,有多份參考文件」的深入研究場合。
首先確認 「設定」=>「輸出語言」 是中文 (或是你要的語言)。
2024年7月23日 星期二
 想要複習大學普通物理, 於是製作了這張圖。
[
想要複習大學普通物理, 於是製作了這張圖。
[2024年1月30日 星期二
vosk: 影片/音檔聽寫機
我比較喜歡閱讀; 不太喜歡看影片/聽podcast。 找到 summarize.tech 這個網站不錯, 餵它一部英文 youtube 影片連結, 就幫你產生文字摘要。 但是它好像只吃有附字幕檔的影片。 那如果是其他語言呢? 我試了 一部自動產生字幕的西班牙文影片, 它會產生英文的文字摘要。 那如果是用 video downloadhelp 抓回來的影片呢? 如果想離線使用呢? 那就安裝 vosk, 在自己的電腦上離線產生各種語言的字幕檔吧!
2023年12月30日 星期六
用亞馬遜的 ec2 雲端主機自架 stable diffusion
在 Amazon 的 AWS 上面重新安裝一次 (其實是好幾次) stable diffusion。 這次用比較簡單的做法。 反正 SD 自己會建立所需要的 python 環境, 所以其實不需要用 CloudFormation, 也不需要特別找 "deep learning" 類型的 AMI (Amazon Machine Image)。 直接從比較簡單的 建立一個 ec2 instance 開始。 建立過程當中, 我做以下的選擇與設定:
2023年12月23日 星期六
自架 aws 雲端主機上的 stable diffusion
[2023/12/30] 改推另一篇: 用亞馬遜的 ec2 雲端主機自架 stable diffusion
終於架好自己的 stable diffusion! 簡單筆記一下參考的連結。 因為我有 aws 的優惠, 所以基本上就照著這篇做: 用 AWS CloudFormation 架設 AUTOMATIC1111 版的 SD。 我這篇的篇名應該加上 「補遺」 才對, 因為重點根本都在 koding work 的文章裡面, 請大家自己去讀 :-)
2023年6月3日 星期六
ChatGPT: 正確與錯誤的使用示範
使用 ChatGPT 之前需要有的兩個最基本觀念: (1) 它被賦予的任務是產生文字, 而不是陳述事實。 (2) 相對於整個網際網路查得到的資訊, 它的知識是滄海一粟。
2022年7月4日 星期一
UMAP 筆記
Uniform Manifold Approximation and Projection (UMAP) 是一個用來降低資料維度的演算法。 如果你把它想成是一個副程式, 它所接收的主要輸入參數以及輸出的資料跟 t-SNE 一模一樣: 輸入一張很大的試算表 (例如幾百或幾千個數字欄位、 幾萬甚至幾十萬列), 它可以產生一張新的試算表, 裡面只剩少少幾個數字欄位 (個數由你指定), 這些新欄位的值可以說是原始許多欄位的 "摘要", 如果欄位數夠少 (例如剩下 2 或 3), 你甚至可以把資料畫在螢幕上或呈現在3度空間中, 或許用肉眼就可以觀察出幾萬/幾十萬個點如何分佈在幾個明顯的群 (cluster) 當中。 我在 t-SNE 幫你看見高維度數值資料 以及 撞臉偵測器 兩篇文章當中有實作兩個例子, 可以直接在網頁上玩玩看。 UMAP 比 t-SNE 的速度更快、 效果更好。 我還沒寫程式, 先筆記一下搜尋到的連結。
2021年4月4日 星期日
2019年10月12日 星期六
Keras MobileNet 版的圖片辨識遷移學習
這學期的 AI 課程改用 google colab。 因為它對 caffe 的支援不佳, 所以先前 用 caffe 做遷移學習的範例 不能拿來上課了。 還好搜尋到很棒的一篇教學文 Transfer Learning using Mobilenet and Keras 以及伴隨的 github 專案 ferhat00/Deep-Learning, 於是改寫一下重新上架成為: ckhung/keras-mobilenet。 圖像辨識的整個流程變得超級簡單!
先下載 ckhung/keras-mobilenet 及訓練資料集 dog_behaviors.zip, 再上傳到你的 google drive。 假設你已玩過 google colab, 那麼從 google drive 裡面打開 km-transfer.ipynb 應該就會自動進入 colab。 接下來就照著 km-transfer.ipynb 做囉!
google 圖片搜尋批次下載
 玩機器學習時, 需要有大量的訓練資料。
以圖片辨識來說, google 圖片搜尋是最佳幫手。
但是要手動把搜尋結果一張一張存檔, 很累呀!
這時可以用 github 上 (有五、六千顆星) 的
google-images-download 來批次下載。
玩機器學習時, 需要有大量的訓練資料。
以圖片辨識來說, google 圖片搜尋是最佳幫手。
但是要手動把搜尋結果一張一張存檔, 很累呀!
這時可以用 github 上 (有五、六千顆星) 的
google-images-download 來批次下載。
2019年8月3日 星期六
簡單語音指令辨識
完整的自然語言語音辨識很複雜; 但在很多應用場合中, 如果可以讓用戶以十來個簡單語音指令控制電器/電腦/apps, 就已經很方便了, 而想要訓練這樣的類神經網路, 門檻當然比完整的語音辨識低很多。 Simple Audio Recognition (以下簡稱 SAR 一文) 所介紹的 tensorflow 原始碼當中的 speech_commands 範例, 就是這樣的工具。 餵一段一秒鐘的聲音, 它會判斷這是 "yes", "no", "up"、 "down"、 "left"、 "right"、 "on"、 "off"、 "stop"、 "go" 當中的哪一個語音命令, 或是未知的聲音 (UNKNOWN) 或是無聲 (SILENCE) (其實可能是很小聲的背景噪音)。 假設讀者已經先照著 貴哥的 colab 初學筆記 認識了 colab 的基本操作, 今天這篇文章將接續著帶大家用 colab 把 speech_commands 的操作流程幾乎走一遍。
2019年7月13日 星期六
貴哥的 colab 初學筆記
Google colaboratory 提供短暫 (數小時) 的免費雲端 GPU 算力, 真是深度學習初學者的福音啊! 前提是你要有 google drive 的帳號, 並且略會操作 Jupyter Notebook。 網路上已有很多入門教學文; 貴哥一看到有 shell 可用, 忍不住就好奇多探索一些, 於是也寫一篇自己的初學筆記。 基於 「站在巨人肩膀上」 的原則, 比較多人介紹的基本操作就只簡單帶過, 細節可參考 台大機械所 Wei-Hsiang Wang 的 Colab 基本操作筆記 (中文) 及 fuat 的 Google Colab Free GPU Tutorial (英文)
2018年12月11日 星期二
拿公投統計資料學 pandas
2018年10月17日 星期三
YOLO 自動框出相片裡的人/動物/生活用品
 今天介紹的這個神奇好物, 看圖就知道了。 我偷懶把三張圖擠在一起。
底層是繁忙的街道圖; 左上是森林裡幾隻吃素的 (絕對不包含韓國瑜);
右上是巴黎鐵塔餐廳的一張餐桌。 神奇的 YOLO 技術
把圖裡的人/動物/物件都標示出來了,
而且, 在 cpu-only 的電腦上, 每張圖只花幾秒鐘!
今天介紹的這個神奇好物, 看圖就知道了。 我偷懶把三張圖擠在一起。
底層是繁忙的街道圖; 左上是森林裡幾隻吃素的 (絕對不包含韓國瑜);
右上是巴黎鐵塔餐廳的一張餐桌。 神奇的 YOLO 技術
把圖裡的人/動物/物件都標示出來了,
而且, 在 cpu-only 的電腦上, 每張圖只花幾秒鐘!
2018年9月29日 星期六
快速畫風移轉: 你的圖片/相片/影片, 以名畫家的動漫風格重現!
兩年前的此時, 畫風轉移魔法引發熱烈討論。 我有自己架起來玩過, 很好玩, 但光是轉一張圖就要好幾個小時。 這兩年來, 不斷有人提出改良版的演算法。 目前最佳的版本稱為 fast style transfer, 如果不計算預先訓練畫風的時間, 只計算轉移的時間, 速度超快。 即使是在我的 2014 年老電腦上只用 CPU (Intel Pentium G2030 @ 3.00GHz) 也能處理影片。 下圖每塊 212x120 的 13 秒影片各約耗時 3.5 到 4 分鐘。
2018年8月1日 星期三
自架臉部表情判讀服務
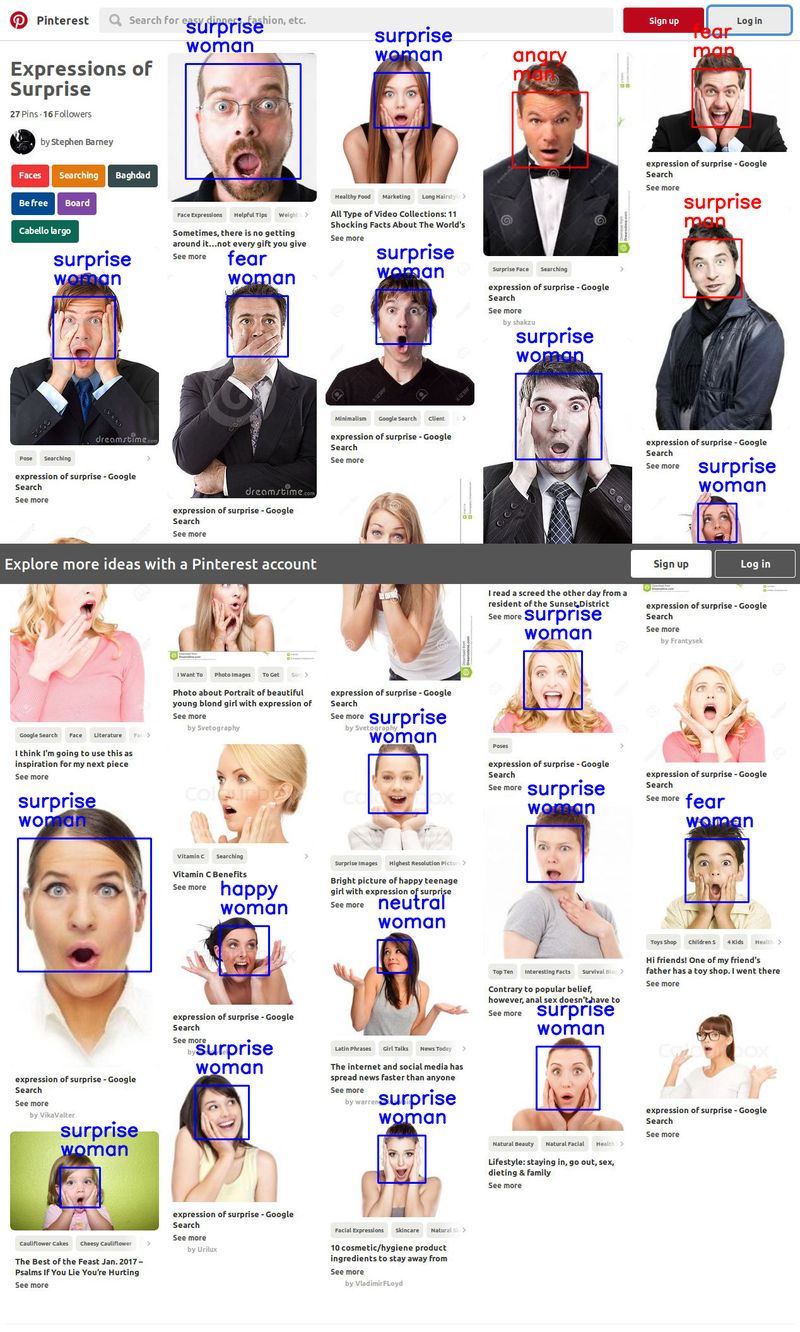 請看一下
原始網站: 我把這個判讀臉部表情 (及性別) 的程式 複製回來並小改一下,
然後打包成
face_classification docker 讓大家玩。
情緒判斷還蠻有一點像的; 可是鬍子先生為什麼竟然被判斷成女性呢?
請看一下
原始網站: 我把這個判讀臉部表情 (及性別) 的程式 複製回來並小改一下,
然後打包成
face_classification docker 讓大家玩。
情緒判斷還蠻有一點像的; 可是鬍子先生為什麼竟然被判斷成女性呢?
2018年7月26日 星期四
躲在 apache2 後面的 flask 範例, 含上傳檔案
 github 上面很多 ML/DL/AI 程式都以 python 撰寫,
可以從命令列執行。 但如果想要佈署,
例如想讓樹莓派可以把野外蒐集到的畫面或聲音傳回伺服器用
AI 程式判讀/分類, 那該怎麼辦呢?
常見的方法是用 flask 架一個簡單的 web server。
Flask 是 python 的一個模組, 所以從那裡要接上
python 所寫的 ML/DL/AI 引擎很方便。
Flask 單獨作為 web server 的方法很簡單, 請見
github 上面很多 ML/DL/AI 程式都以 python 撰寫,
可以從命令列執行。 但如果想要佈署,
例如想讓樹莓派可以把野外蒐集到的畫面或聲音傳回伺服器用
AI 程式判讀/分類, 那該怎麼辦呢?
常見的方法是用 flask 架一個簡單的 web server。
Flask 是 python 的一個模組, 所以從那裡要接上
python 所寫的 ML/DL/AI 引擎很方便。
Flask 單獨作為 web server 的方法很簡單, 請見
訂閱:
文章 (Atom)

