 大人問小孩: 「全世界的玩具隨便你挑? 這怎麼可能?
如果我要的玩具只有一個, 正好又被別人借走了呢?」
大人問小孩: 「全世界的玩具隨便你挑? 這怎麼可能?
如果我要的玩具只有一個, 正好又被別人借走了呢?」對,已經有很多語音辨識的產品了; 但我偏好自由軟體解決方案, 例如以 OpenAI 的 whisper 聽寫模型為引擎的各種解決方案。 如果你的電腦夠好, 也許可以用 Buzz, 它支援三大桌面系統、 有圖形介面、 可以完全在本機執行。 我則是搜尋到美女的影片就被說服選用 Whisper ASR webservice 了:
2026年7月6日 星期一
創建一部 aws 短命 ec2 主機, 省錢玩 AI
AWS 的 ec2 服務, 如果要玩 AI, 就需要選比較強的虛擬主機, 尤其因為有 GPU, 當然也就比較貴 💸。 大部分時候, 直接拿別人包好的 docker 來玩比較方便, 而且還要設定讓 docker 支援 GPU。 但我只是久久才偶爾開來玩一次, 要怎樣才能省錢?
2026年5月24日 星期日
LocalSend: 同區網內任意裝置互傳檔案 (免註冊、免雲端)
跨系統傳檔案,非得要把隱私送給雲端硬碟,或是忍受通 line 壓縮畫質嗎? 讓 LocalSend 來簡化問題吧! 只要在同一個區網裡, 三大桌面系統 (Linux、 Windows、 MacOS) 及兩大手機系統 (Android、 iOS) 的裝置都可以任意互傳檔案、 這邊複製那邊貼上。 跟任何雲端服務完全沒有關係; 彼此也不需要事先認識, 什麼加好友的通通都不用。 如果現場沒有共同的 wifi, 也可以把自己的手機當成無線基地台 (行動熱點) 請大家連線, 傳完檔案之後就可以把無線基地台跟 app 都關掉, 彼此分道揚鑣。 像這樣去中心化的工具, 如果夠多人安裝, 對於社會的 #網路韌性 會有很大的幫助。 如果你關心這個議題, 辦活動時請盡量鼓勵大家 下載安裝自由軟體 LocalSend。
2026年5月3日 星期日
畫氣泡圖挑選性價比最佳的租賃 LLM
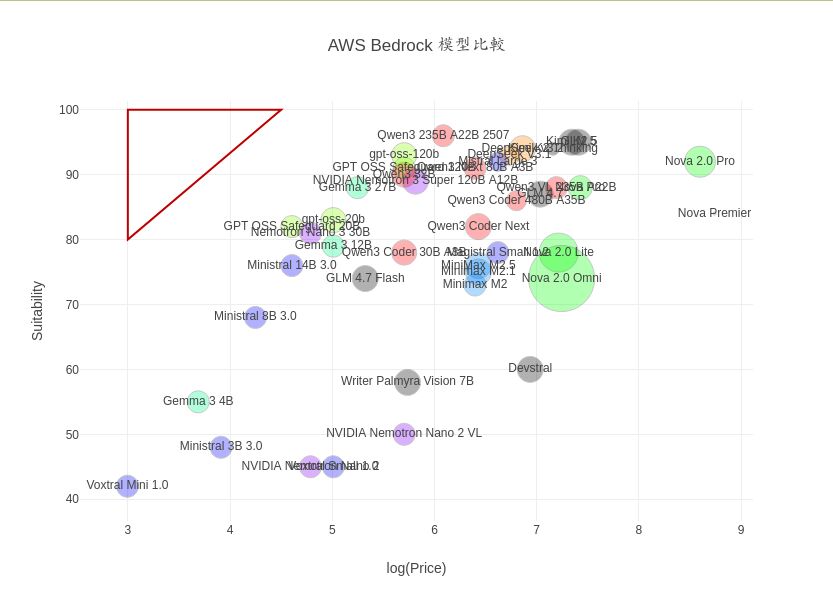 你挑了一個 LLM 租賃服務, 它提供很多模型。 該怎麼選?
我就拿 aws 的 bedrock 為例來解說資料視覺化 (散點圖/氣泡圖)
如何幫我們挑選性價比最佳的 LLM。
這些步驟應該也大致適用於比較整理其他 (來自同一家) 供應商的模型清單 -
只要你可以先建立一個 csv 檔列出該廠商提供的所有選項,
類似
我為 bedrock 建立的 bedrock-pricing.csv。
你挑了一個 LLM 租賃服務, 它提供很多模型。 該怎麼選?
我就拿 aws 的 bedrock 為例來解說資料視覺化 (散點圖/氣泡圖)
如何幫我們挑選性價比最佳的 LLM。
這些步驟應該也大致適用於比較整理其他 (來自同一家) 供應商的模型清單 -
只要你可以先建立一個 csv 檔列出該廠商提供的所有選項,
類似
我為 bedrock 建立的 bedrock-pricing.csv。
2026年4月25日 星期六
把買 GPU 的錢省下來租雲端服務: 建立 aws bedrock 模型與價格清單
想玩龍蝦 🦞、 不想買 GPU => 租雲端的 LLM 來用。 因為我有 AWS 的點數, 那就拿 AWS BedRock來用吧!
[7/8] 補充說明: 但 aws 其實比較貴。 如果你不像我有點數, 建議問一下 AI: 「有哪些可替代 AWS Bedrock 和 OpenRouter、可租用開放權重模型的平台? 請比較 AWS Bedrock、OpenRouter 以及你推薦的其他方案的價格(以整體概況為主)。 另外,也請比較它們所提供的模型種類 (多樣性),以及其他你認為重要的面向。」 Gemini 跟 ChatGPT 都推薦 DeepInfra。 另外還有 Together AI、 Groq、 Novita AI 等等。
回到 AWS BedRock。 請參考: 給小白的 bedrock 簡介、 bedrock 網頁介面試用心得。 不過, 我喜歡下指令, 所以是在 debian 上面安裝 awscli 套件來測試。 假設你已經 用 aws configure 命令設定好 access key, 也略微熟悉 jq。 我們的目的只是要跟 OpenClaw 接軌, 所以只關心有哪些模型可選擇、 如何下簡單的呼叫指令, 以及價格。
2026年4月24日 星期五
ollama 雜記: 模型檔案位置與大小
想在自己的電腦離線跑AI, 就要安裝模型管理器 ollama。 Ollama 安裝、模型比較、硬體需求與工具整合 之類的中文教學資訊已經很豐富。 我這裡只補充記錄一點沒那麼容易找到的資訊。
在 linux 底下, 安裝完成之後, 用 ollama pull ...
下載回來的模型的相關檔案都放在這裡:
/usr/share/ollama/.ollama/models/ 。
其下有兩個子目錄: blobs/ 底下是真正的模型檔 (佔很大的空間);
manifests/registry.ollama.ai/library/ 子目錄底下則是元資料,
就是描述每個模型的資訊。
2026年3月14日 星期六
收集學生的作業? filebrowser 比教學資訊系統更好用
 我一直覺得各種教學資訊系統 (Learning Management System,
不論是否自由軟體, 例如 moodle 或 iLearning 等等) 的交作業功能都不好用。
Google drive 也許好一點;
但對老師最方便的方式, 還是讓學生把作業上傳到我的 linux 伺服器。
這樣, 我在可以直接用 grep 之類的指令批次處理所有作業, 比滑鼠點半天快太多了。
但除了幫學生開設 ssh 帳號、 教 (通識!) 學生採用 putty 跟 winscp 傳檔之外,
還有其他方式嗎?
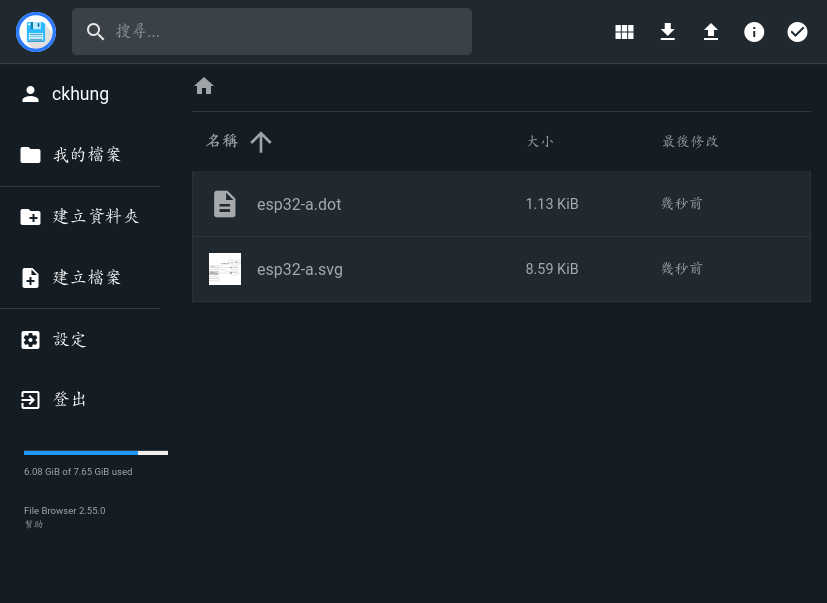
詢問 gemini 🤖 的意見, 它推薦
File Browser。
我一直覺得各種教學資訊系統 (Learning Management System,
不論是否自由軟體, 例如 moodle 或 iLearning 等等) 的交作業功能都不好用。
Google drive 也許好一點;
但對老師最方便的方式, 還是讓學生把作業上傳到我的 linux 伺服器。
這樣, 我在可以直接用 grep 之類的指令批次處理所有作業, 比滑鼠點半天快太多了。
但除了幫學生開設 ssh 帳號、 教 (通識!) 學生採用 putty 跟 winscp 傳檔之外,
還有其他方式嗎?
詢問 gemini 🤖 的意見, 它推薦
File Browser。
這是一個很簡單的雲端檔案服務: 從客戶端看, 每位同學可以有自己的帳號密碼, 用瀏覽器就可以上傳檔案。 在伺服器端, 所有的檔案都由啟動服務的那一個人所擁有。 我習慣讓同學們可以看到自己上傳過的檔案、 看到彼此的作業。 由我的帳號 ckhung 來啟動服務, 正好。
2026年1月22日 星期四
星際大戰角色同框頻率視覺化 (graphviz 飆速初體驗 / 用 jq 把 json 轉 csv / perl 的試算表模式)
 想知道誰最常跟莉雅公主同框嗎? 不用人工計算,我們用幾行指令就能畫出來。
StarWars-social-network
這個專案整理了六集的星際大戰裡每一集內的角色同框頻率。
我們用 graphviz 把它畫出來, 順便學一下如何用 jq 把 json 格式轉成 csv,
以及 perl 處理 csv 檔的好用模式。
想知道誰最常跟莉雅公主同框嗎? 不用人工計算,我們用幾行指令就能畫出來。
StarWars-social-network
這個專案整理了六集的星際大戰裡每一集內的角色同框頻率。
我們用 graphviz 把它畫出來, 順便學一下如何用 jq 把 json 格式轉成 csv,
以及 perl 處理 csv 檔的好用模式。
2026年1月18日 星期日
 又是一篇中興大學通識課要用的講義。
對長期讀者來說, umap 的部分是重播; 不過 gemini 的部分可以參考。
又是一篇中興大學通識課要用的講義。
對長期讀者來說, umap 的部分是重播; 不過 gemini 的部分可以參考。
2026年1月10日 星期六
(在自己電腦上執行的) 紫微斗數命盤
 我建立了 ZiWeiDouShu 專案,
裡面有 perl、 python、 javascript 三個版本,
都可以在自己的電腦上執行, 不用交出你的隱私!
我建立了 ZiWeiDouShu 專案,
裡面有 perl、 python、 javascript 三個版本,
都可以在自己的電腦上執行, 不用交出你的隱私!
- 用萬年曆找出陰曆的生年月日及時辰。
- 例如甲寅年5月7日申時生, 則可在命令列上這樣執行:
> python3 ZiWeiDouShu.py 1 3 5 7 9 # 或是 perl ZiWeiDouShu.pl 1 3 5 7 9
python 版跟 perl 版都各自只有一個程式檔, 不需要其他任何檔案。 甲是1,乙是2,...癸是0(寫10也可以); 子是1,丑是2,...亥是0(寫12也可以)。 - ckhung-gem.md 是我在 gemini 裡面用的 gem, 請參考。 要詢問 AI 時, 不要貼 (輸出上方的) 命盤圖給它看, 要貼 (輸出下方) 條列式的, 它比較好解讀。 最前面手動加上一句 「G先生 19xx年生」 之類的, 重點是提供: 稱謂、 性別、 西元生年這三項 (程式沒處理的) 資訊。
- examples/ 目錄裡面有川普、 馬斯克、 習近平的命盤輸入範例可參考。
[1/16 新增離線 javascript 版] 或是確認 ZiWeiDouShu.html、 ZiWeiDouShu.css、 ZiWeiDouShu.js 這三個檔在同一個目錄裡, 然後用瀏覽器打開 html 檔、 填入生辰資訊、 按下「產生命盤」 即可。
下面就來說說這支程式的開發過程以及我的使用方式吧。
2026年1月4日 星期日
gemini 的 gem 新手小作: 懶人的媒體識讀助理
 這幾天開始學 gemini 的 gem。 筆記一下心得。
這幾天開始學 gemini 的 gem。 筆記一下心得。
其他 AI 的類似功能: ChatGPT: 我的 GPT、 ...
一、 試車
- (非必須) 建議先設定好自己的 saved-info。
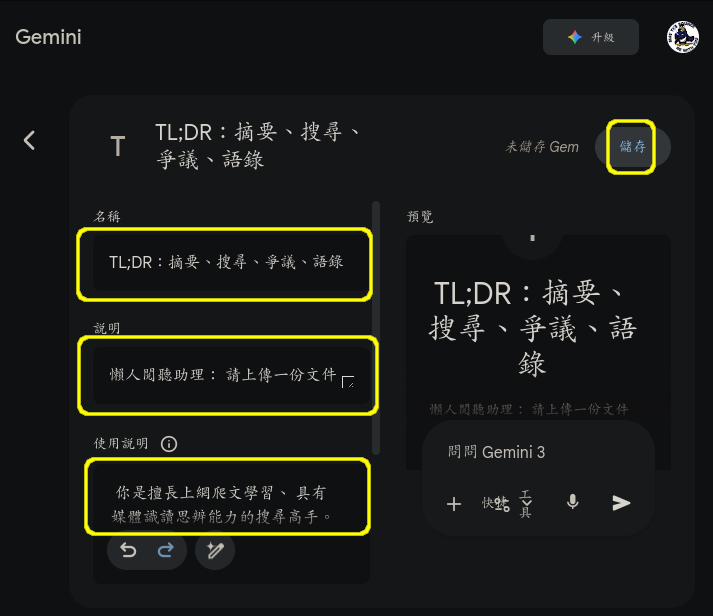
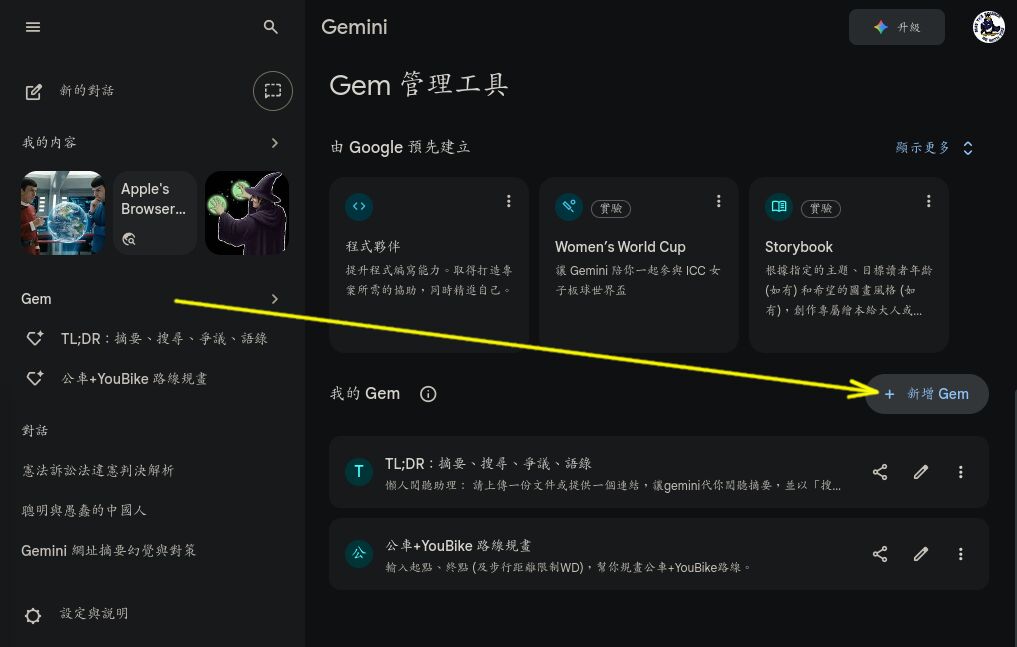
- 點選左側主選單的 「Gem」 再點 「我的 Gem」 右側的 「新增 Gem」。
- 打開我設計好的 tldr-gem.txt, 把 「名稱」、 「說明」 以及一大段提示詞分別複製貼進去, 然後按 「儲存」, 這個就可以用了。 會出現在左側主選單。
- 你可以編輯, 改成自己想要的樣子。 (提示詞寫好之後, 我自己都會另外備份。) 也可以點提示詞輸入框最下面的 "魔術筆" 讓 gemini 幫你潤稿。 事實上, 上面那個內容就是 gemini 幫我潤稿過的, 英文標題分段也是它加的。
TL;DR (too long, didn't read) 是一個隨時不忘查驗事實的懶人閱聽助理。 推薦這幾則影片 邀請大家分別測試看看:
2025年12月31日 星期三
saved info 讓你跟 gemini 超頻倍速溝通
 [6/28 重寫大部分] 現在不叫做 saved info (但這個關鍵詞還是可以找到很多文章),
而是在 "settings" => "personal intelligence" 底下, 分成兩部分。
基於隱私考量, 第一部分 "memory" 我還是不想啟用;
本文內容適用於第三部分 "instructions for Gemini"。
[6/28 重寫大部分] 現在不叫做 saved info (但這個關鍵詞還是可以找到很多文章),
而是在 "settings" => "personal intelligence" 底下, 分成兩部分。
基於隱私考量, 第一部分 "memory" 我還是不想啟用;
本文內容適用於第三部分 "instructions for Gemini"。
在舊版裡, 我直接以 (星艦迷航記的) Spock 為原型來設定 gemini 的個性。 但最近 (6/28) 更新時發現: 現在如果提到 Spock, gemini 就拒絕存檔!? (是 哪個舊情人 在不爽 Spock 嗎?) 沒關係, 你還是可以把他的特性描述出來。 另外, 每一則不能有太多字; 太長的指令要拆開。 我因為開始玩 Hermes Agent 而順便重新整理 「給 gemini 的指令」, 把前者的 SOUL.md 跟 USER.md 的內容 copy 過來 gemini。
電腦的速度比人腦快很多, 所以人類跟 LLM 之間的溝通, 最高速率取決於人腦自己的極限。 如果溝通管道設計不良, 成為瓶頸, 那麼效率就還會再打折扣。 我想把我跟 gemini 之間的溝通頻寬拓展到 (我自己的) 極限, 所以寫了這個 saved-info (中文翻譯) 當作我的 "saved info"。 這樣, gemini 會在你未來的每一次對話指令之前自動加上這些指令。 這篇說明一下我的 saved info 的設計理念。
其他 AI 的類似功能: 自訂 ChatGPT、 ...
訂閱:
文章 (Atom)

