 大人問小孩: 「全世界的玩具隨便你挑? 這怎麼可能?
如果我要的玩具只有一個, 正好又被別人借走了呢?」
大人問小孩: 「全世界的玩具隨便你挑? 這怎麼可能?
如果我要的玩具只有一個, 正好又被別人借走了呢?」你有一個試算表, 其中有一個數字欄位 (例如金額/人口/面積), 還有一個文字欄位 (例如商品名稱/團隊名稱/姓名), 現在想要根據這個文字欄位來對數字欄位分項/分組加總, 把相同商品名稱 (或相同團隊名稱、 或相同姓名) 的所有列的數字欄位全部累加起來, 該怎麼做? 在 LibreOffice/OpenOffice/google sheet/excel 等等各家試算表軟體裡面, 都有 (1) subtotal (2) pivot table (3) sumif 三種方式都可以達到相同的效果。 本文採用 LibreOffice Calc, 分別以這三種方法來處理這兩個範例:
- 處理 blockbuster.csv 「有史以來票房前五十名的電影及導演列表」 (從 1 和 2 整理出來的) 從而製作出 「導演-導過最賣座幾部片票房總額」 的對照表 ( 成果檔)。
- 處理 countries.csv 「全球各國人口及面積列表」, (從 這裡 整理出來的) 從而製作出 「六大洲人口密度列表」 ( 成果檔)。
這三個方法也可以拿來應用於統計各國奧運得獎數、 朋友旅遊結束後拆帳、 公司部門之間比較績效等等場合。
方法一: subtotal
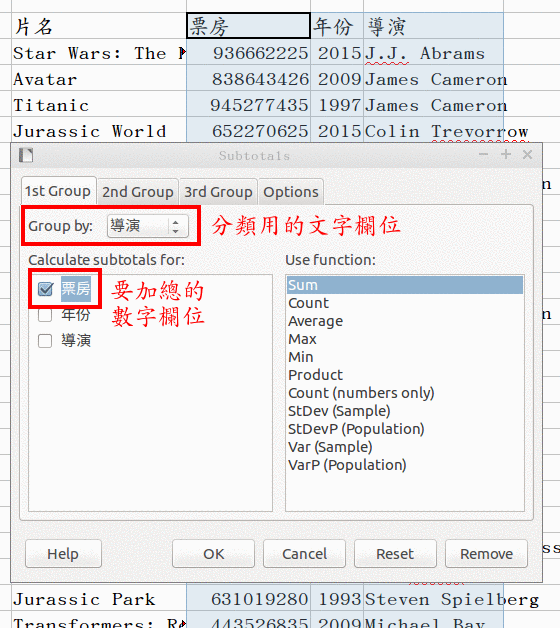
- 框選原始資料, 含第一列表頭 (欄位名稱)。
- Data => Subtotals
- "group by" 選 「分類用的文字欄位」 (導演姓名或洲別); "calculate subtotals for" 勾選 「要加總的數字欄位」 (票房/人口/面積)
這個方法步驟最少、 也有很方便的各種函數可選, 不限加總 (可求各組最大最小等等)。 唯一的缺點是它把結果跟原始資料混在一起, 看起來很雜亂, 也不方便後續處理。 以上參考 OO.o 官網 subtotal 文件。
方法二: pivot table 樞紐表
各家試算表軟體裡面都有一個 pivot table 樞紐表 的功能 (在舊版的 OO.o 當中叫做 data pilots) 可以處理我們的問題。
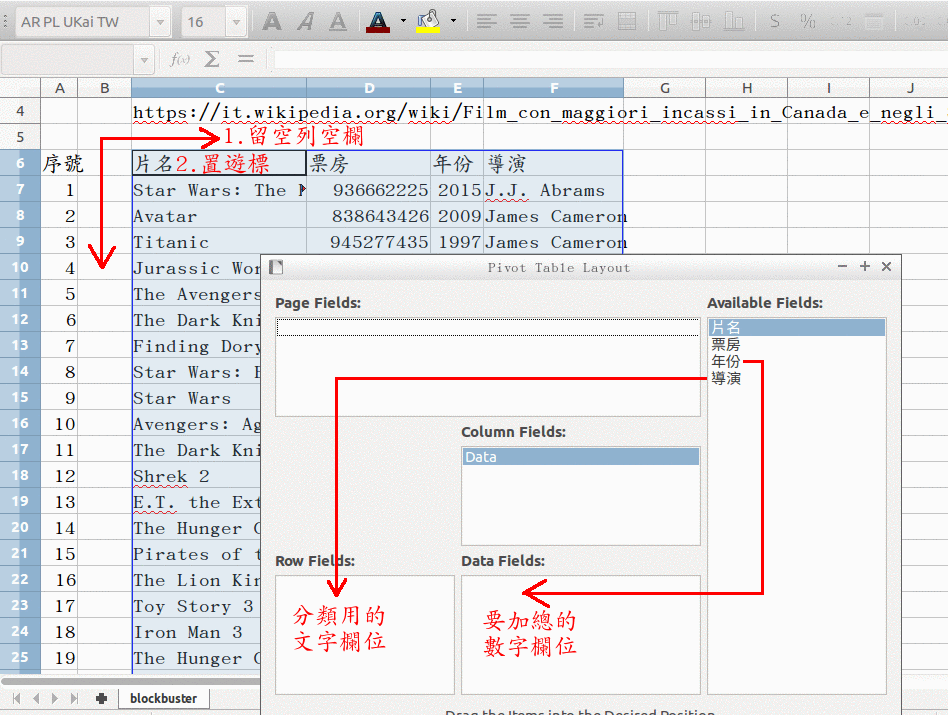 在原始表格 (包含最上面「各欄位名稱」那一列表頭, 重要!)
的上下左右四週各留至少一列/一欄空白。
在原始表格 (包含最上面「各欄位名稱」那一列表頭, 重要!)
的上下左右四週各留至少一列/一欄空白。
- 把遊標放在原始表格的左上角即可 (第一欄的欄位名稱那一格), 不必選取整個表格。
- 從選單的 「Insert」 叫出 「Pivot Table」。
- 選預設的 「current selection」 即可。
- 從右側 「availabel fields」 把 「導演」 (想要拿來分類的文字欄位名稱) 拉到左側的 「row fields」; 把 「票房」 (想要加總的數字欄位名稱) 拉到中間的 「data fields」。
- 按 「OK」, 就會在一個新的分頁產生分類加總表格。
pivot table 產生之後, 就不太方便隨意編輯。 我喜歡複製, 然後用 edit => paste special 把它的文字數字內容貼到原始表格旁邊,再做後續處理。
如果原始表格內有好幾個數字欄位, 還可以把它們全都拉到 data fields, 這樣就可以對各個數字欄位分別分類加總。 例如計算六大洲人口密度時, 就可以把 Population 跟 Area 拉到 data fields 各自按照洲別加總。 (至於 GDP、 壽命、 出生率、 死亡率等等數字就免了 -- 加總沒什麼意義。) 注意: 這種情況下, 請不要去動那個原本位於 「column fields」 的 「data」。 我原先把它拉到右側 「availabel fields」 (丟掉), 結果出來的加總變成每分類底下有好幾列數字垂直疊在一起, 醜醜的又不便後續處理。
如果把兩個文字欄位拉到 row fields, 就會產生 「主分類-子分類」 的效果。
以上參考這篇: Data Pilots (Pivot Tables) in OpenOffice Calc。
方法三: unique filter 去除重複列, 再 sumif 條件加總
 喜歡鍵盤文字勝過滑鼠選單的讀者可能會偏好這個方法。
喜歡鍵盤文字勝過滑鼠選單的讀者可能會偏好這個方法。
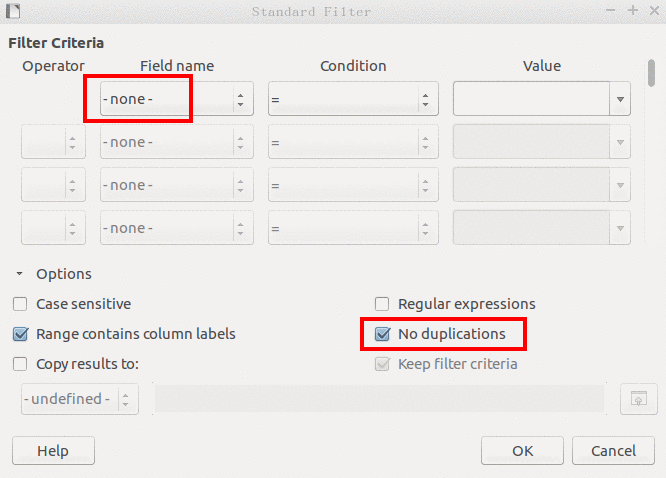
- 把分類/分項那一欄 (例如導演姓名或六大洲別) 的所有內容 (不包含標頭欄位名稱) 剪貼到一個新分頁。
- 在新分頁上對複製過來的新資料排序: Data => Sort Ascending
- Data => More Filters => Standard Filters 叫出 filter 對話框。
- 不要有任何過濾條件 (第一列的 field name 改成 "-none-"), 要勾選 "no duplications", 按 OK 產生分類/分項名稱清單。 (所有導演姓名, 或六大洲名稱, 各只出現一次。)
- 把結果複製貼上回原始資料分頁的旁邊。
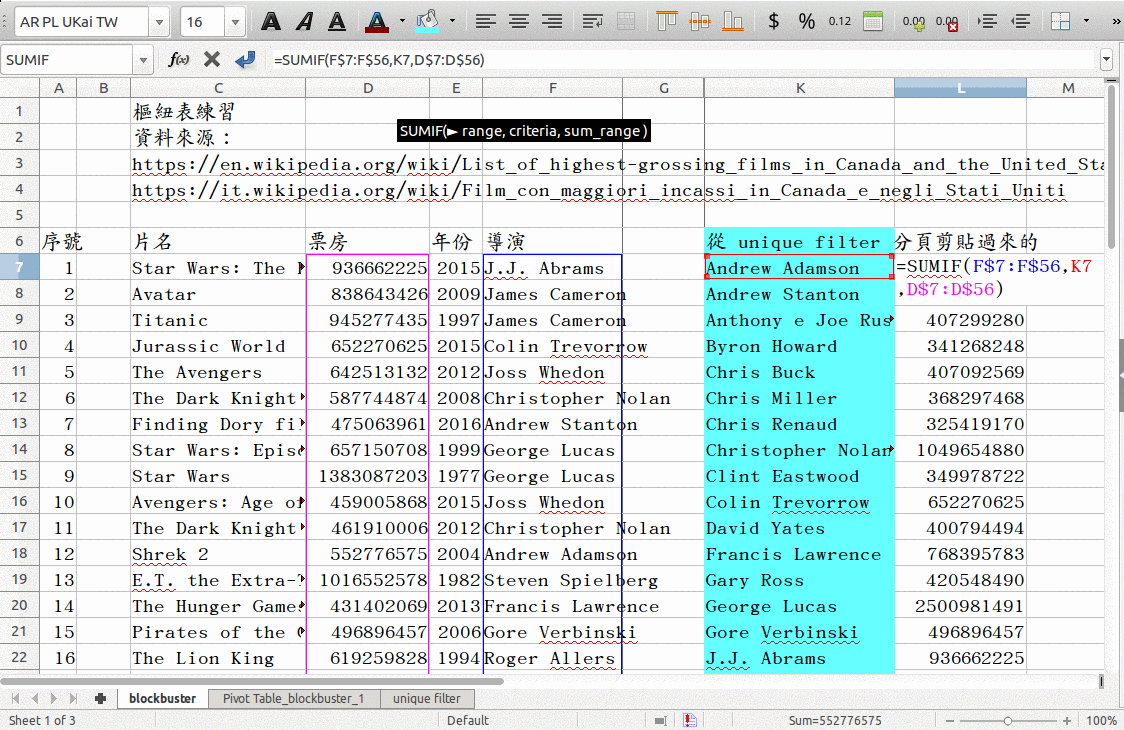 在導演姓名或六大洲旁邊加上 sumif 運算式。
如圖, 原始資料的導演姓名在 F 欄,
要加總的是 D 欄的票房, 去除重複的導演姓名清單在 K 欄,
所以 L7 的公式長得像這樣:
在導演姓名或六大洲旁邊加上 sumif 運算式。
如圖, 原始資料的導演姓名在 F 欄,
要加總的是 D 欄的票房, 去除重複的導演姓名清單在 K 欄,
所以 L7 的公式長得像這樣:
sumif(F$7:F$57, K7, D$7:D$56)。 「拿 K7 的姓名去 F 欄查, 相同的話就把 D 欄的數字納入總和。」 然後就可以用 L7 的公式填滿 L 欄。
如果你習慣用命令列, 可以這樣取代 1 到 4 步:
先將分類欄的內容剪貼到 names.txt 文字檔, 再下這個指令:
sort names.txt | uniq -c 。
Gnumeric 試算表不支援 pivot table 跟 subtotal/group-by,
就必須採用這種方式。
採用這個方法, 除了可以用 sumif 分項/分類/分組求和, 也可以用 countif 數每項/每類/每組含有幾列, 進而再從這兩組數字求出各項/各類/各組的平均值、 標準差等等統計數據; 但無法求各項/各類/各組的最大最小值。


沒有留言:
張貼留言
因為垃圾留言太多,現在改為審核後才發佈,請耐心等候一兩天。