 大人問小孩: 「全世界的玩具隨便你挑? 這怎麼可能?
如果我要的玩具只有一個, 正好又被別人借走了呢?」
大人問小孩: 「全世界的玩具隨便你挑? 這怎麼可能?
如果我要的玩具只有一個, 正好又被別人借走了呢?」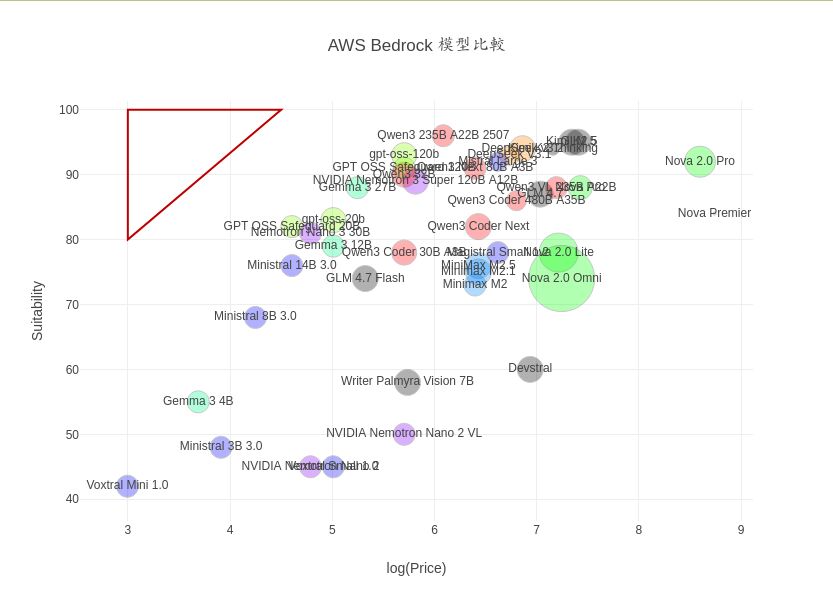 你挑了一個 LLM 租賃服務, 它提供很多模型。 該怎麼選?
我就拿 aws 的 bedrock 為例來解說資料視覺化 (散點圖/氣泡圖)
如何幫我們挑選性價比最佳的 LLM。
這些步驟應該也大致適用於比較整理其他 (來自同一家) 供應商的模型清單 -
只要你可以先建立一個 csv 檔列出該廠商提供的所有選項,
類似
我為 bedrock 建立的 bedrock-pricing.csv。
你挑了一個 LLM 租賃服務, 它提供很多模型。 該怎麼選?
我就拿 aws 的 bedrock 為例來解說資料視覺化 (散點圖/氣泡圖)
如何幫我們挑選性價比最佳的 LLM。
這些步驟應該也大致適用於比較整理其他 (來自同一家) 供應商的模型清單 -
只要你可以先建立一個 csv 檔列出該廠商提供的所有選項,
類似
我為 bedrock 建立的 bedrock-pricing.csv。
首先根據模型名稱排序一下, 觀察同一模型 (例如 gpt-oss-20b) 的諸多不同選項:
... OpenAI,gpt-oss-20b,,0.0002000000,EUC1-gpt-oss-20b-output-tokens-flex OpenAI,gpt-oss-20b,,0.0002000000,EUS1-gpt-oss-20b-output-tokens-batch OpenAI,gpt-oss-20b,,0.0002000000,EUS1-gpt-oss-20b-output-tokens-flex OpenAI,gpt-oss-20b,,0.0002300000,EUW2-gpt-oss-20b-output-tokens-batch OpenAI,gpt-oss-20b,,0.0002350000,EUW2-gpt-oss-20b-output-tokens-flex OpenAI,gpt-oss-20b,,0.0003000000,EUN1-gpt-oss-20b-output-tokens OpenAI,gpt-oss-20b,,0.0003000000,USE1-gpt-oss-20b-output-tokens OpenAI,gpt-oss-20b,,0.0003000000,USE2-gpt-oss-20b-output-tokens OpenAI,gpt-oss-20b,,0.0003000000,USW2-gpt-oss-20b-output-tokens ...
以 aws 的收費方式還有我的初學者情境來說, 要挑的就是最便宜的 "flex"。
實際使用時要考慮 ouput 及 input, 不過我就偷懶假設兩者大致等比例連動。
那就以價格較高的 ouput 為主好了。
另外,有些模型沒有分 service tier,也就是,它不含 "flex" 字串,tier 欄位是空的。
把以上這些全部抓出來、 刪掉含有 "priority" 的 (聽起來就比較貴) 及含有 "batch" 的 (跟 flex 差不多價格):
perl -F, -nale 'print if ($F[4]=~/-output-/ and $F[2]=~/^(flex)?$/ and ! /priority|batch/)' bedrock-pricing.csv > inexpensive.csv
資料量從一萬多列降到少於兩千列。
再用 grep gpt-oss-20b output-flex.csv 查看,
發現造成重複的變數現在只剩: 各區伺服器有不同的定價。
... OpenAI,gpt-oss-20b,flex,0.0001545000,APS2-openai.gpt-oss-20b-mantle-output-tokens-flex OpenAI,gpt-oss-20b,flex,0.0001800000,APN1-openai.gpt-oss-20b-mantle-output-tokens-flex OpenAI,gpt-oss-20b,,0.0001550000,APS4-gpt-oss-20b-output-tokens-flex OpenAI,gpt-oss-20b,flex,0.0001500000,USW2-openai.gpt-oss-20b-mantle-output-tokens-flex OpenAI,gpt-oss-20b,,0.0002000000,EUC1-gpt-oss-20b-output-tokens-flex ...
手動在 inexpensive.csv 最上面加上標題列: Provider,Model,Tier,Price,Usagetype,
又截取部分的資料丟給 AI 看, 叫它寫一個 python 程式
price-pct-by-model.py
按照模型名稱 (第二欄) 分組, 並且以每一組的 P25
(第25百分位數, 也就是每一組的較便宜那一半的中位數) 作為該組的價格。
輸出時, 每一組印一列, 包含供應商、模型名稱、價格*1e6、該組資料共幾筆:
python3 price-pct-by-model.py inexpensive.csv > prices-by-model.csv
現在只剩 75 列, 像這樣:
Provider,Model,Price,Count ... Google,google.gemma-4-e2b,40,4 Mistral,Mistral 7B,220,9 Meta,Llama 3 8B,600,7 Meta,Llama 3.1 8B,220,3 Qwen,Qwen3 VL 235B A22B,1560,31 ,Nova Sonic 2.0,2750,8 Google,google.gemma-4-31b,200,4 ...
這樣的資料已經少到可以直接餵給 AI。 叫它新增一個 quality 欄位, 為每個模型打一個 (AI 自己想的) 0-100 分之間的主觀分數, 評斷依據是我所需要的應用面向。 (下標籤/寫程式/部落格編輯/投資分析師之類的) 成果: br26.csv + 互動散點圖。 (可以選取一小塊區域以便放大) 橫軸是價格的對數; 縱軸是適用度 (性能); 圈圈大小是有多少個區域提供此模型。 性價比最理想的是左上角的圈圈。 最後這個動作我叫 gemini 重做了好幾次, 每次出來的結果差不多。 再挑幾個最佳解叫 ChatGPT 去比較一下。 (基於心智健康理由, 我個人不會考慮中國的模型。)
(順帶一提: 科技報導/科學月刊這篇 「多快好省」的大型語言模型? DeepSeek的優勢、 爭議與國安隱憂 裡面的插圖 (互動版) 就是採用同一軟體 scatplot 與類似的設定畫出來的。)
最後再回到原始的價格清單 bedrock-pricing.csv、
撈出想要的模型約二十幾筆資料、 按價格排序,
挑出有提供此模型的最便宜區域, 像這樣:
(head -n 1 bedrock-pricing.csv ; perl -ne 's#\b(0.00\d+)\b#$1*1e6#e; print if /nemotron-nano-3-30b.*-output.*flex/i' bedrock-pricing.csv | sort -t, -nk 4) > nemotron-nano-3-30b.csv
然後啊, 因為 我對 gemini 的設定 裡面要求它輸出時盡量用學術關鍵詞/術語, 所以也順便學到一個名詞 "Pareto Frontier", 也就是我的圖中左上方那一排模型: 「都是算最佳解, 各有不同的取捨」。 再次證明: 有些觀念/想法是很自然的、 很多人都有可能在不知道彼此的狀況下, 各自 "重新發明"。


沒有留言:
張貼留言
因為垃圾留言太多,現在改為審核後才發佈,請耐心等候一兩天。