 大人問小孩: 「全世界的玩具隨便你挑? 這怎麼可能?
如果我要的玩具只有一個, 正好又被別人借走了呢?」
大人問小孩: 「全世界的玩具隨便你挑? 這怎麼可能?
如果我要的玩具只有一個, 正好又被別人借走了呢?」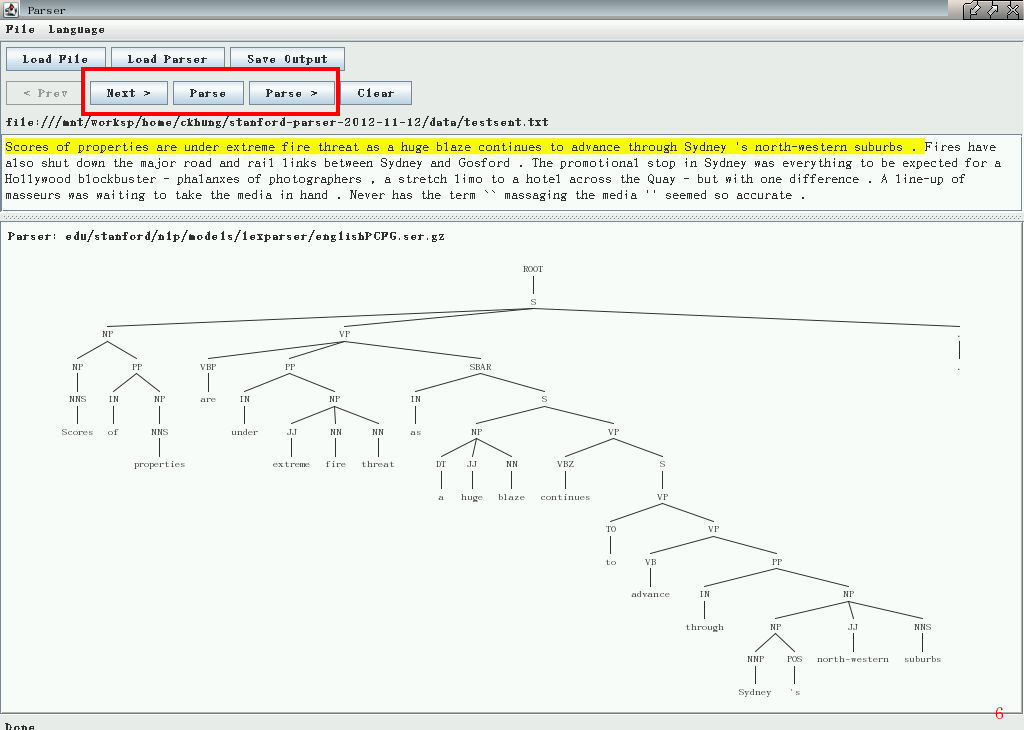 [2013/04/02 為新版改寫]
呵呵, 別想歪了... 今天要介紹的工具之所以不適合小朋友,
並不是因為它含有不恰當的內容, 而是因為它太生硬了 --
用 Stanford Parser 學英文, 沒有趣味生動的遊戲可玩,
只能單純地幫你做 「英語句型文法解析」。
[2013/04/02 為新版改寫]
呵呵, 別想歪了... 今天要介紹的工具之所以不適合小朋友,
並不是因為它含有不恰當的內容, 而是因為它太生硬了 --
用 Stanford Parser 學英文, 沒有趣味生動的遊戲可玩,
只能單純地幫你做 「英語句型文法解析」。
Stanford Parser 是史丹佛大學自然語言研究中心採用 java 語言所撰寫的英文語句文法解析工具。 所以你需要先安裝 java runtime environment 才能使用它。
- 在 debian 系列底下:
apt-get install openjdk-7-jre - 在 rpm 系列底下:
yum install java-1.7.0-openjdk - 在 windows 和 Mac 底下: Oracle Java
然後從
Stanford Parser 官網下載點 取得最新版 2.0.4 解壓縮後進入子目錄。
接著執行: ./lexparser.sh data/testsent.txt
其中最後一個參數是純文字的資料檔, 內含五個英文句子。
輸出一大串資料, 最前面一部分看起來像這樣:
Loading parser from serialized file englishPCFG.ser.gz ... done [5.2 sec].
testsent.txt
Parsing file: testsent.txt with 5 sentences.
Parsing [sent. 1 len. 21]: [Scores, of, properties, are, under, extreme,
fire, threat, as, a, huge, blaze, continues, to, advance, through,
Sydney, 's, north-western, suburbs, .]
(ROOT
(S
(NP
(NP (NNS Scores))
(PP (IN of)
(NP (NNS properties))))
(VP (VBP are)
(PP (IN under)
(NP (JJ extreme) (NN fire) (NN threat)))
(SBAR (IN as)
(S
(NP (DT a) (JJ huge) (NN blaze))
(VP (VBZ continues)
(S
(VP (TO to)
(VP (VB advance)
(PP (IN through)
(NP
(NP (NNP Sydney) (POS 's))
(JJ north-western) (NNS suburbs))))))))))
(. .)))
意思是: 「第一個句子共有 21 個字, 包含一個主要子句, 以及一個由 "as" 所帶領的附屬子句。 主要子句的主詞是 "Scores of properties", 動詞是 "are", 補語是 "under extreme fire threat"...」 其中每個大寫的代號分別代表什麼意義? 請見 簡表。 若需要更完整的資訊, 詳見 Stanford Parser 首頁的 "FAQ" 第三個問題 inventory of tags, phrasal categories, and typed dependencies 所提到的幾個連結。 不過對一般人 (例如貴哥) 而言, 只需要知道子句層級的主要斷點 (上面我加上的黃底部分) 就很夠用了。
當然, 這種呈現方式只有熟悉 lisp 的人才能接受
(換個方式說, 如果一位英文老師可以看懂這種方式,
就表示學習 lisp 語對對她而言可能並不困難)。
對一般人而言, 真正比較常用的, 是圖形介面的版本: ./lexparser-gui.sh
(在 Windows 下可以點選 lexparser-gui.bat)
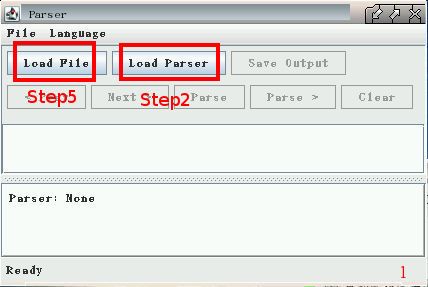
這只是一個圖形介面的空殼。 想要載入真正的分析器 (parser),
必須按下 "Load Parser" 按鈕, 選擇 *-models.jar 那個檔案 (圖2)
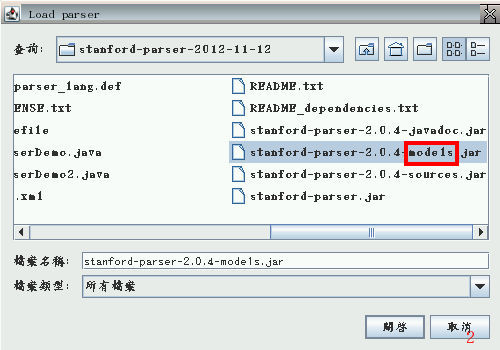
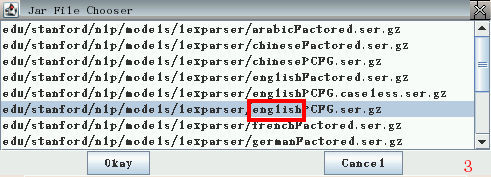
不要急著按 Okay! 要先任選一個 *english* 分析器 (圖3)
再按 Okay。 等很多秒之後, 下方就會出現 "Loaded parser" 的訊息。 (圖4)
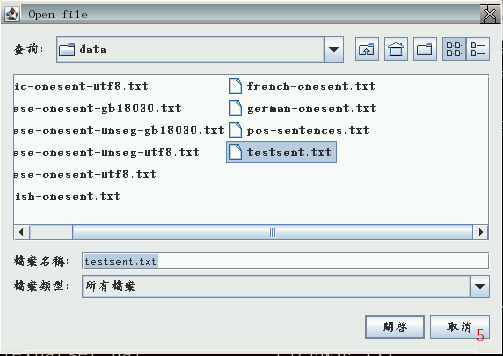
最後, 按下 "Load File" 按鈕, 載入欲分析的英文文句純文字檔
-- 例如內附的 data/testsent.txt。 (圖5)
隨便點一句 (被選到那一句的底色會變黃) 按下 「Parse」 分析它。 圖6 是 Stanford Parser 分析 data/testsent.txt 第一個句子的結果。
除了 "用華爾街日報的文章訓練出來的" wsjPCFG.ser.gz 與 wsjFactored.ser.gz 之外, 甚至還有德文、 阿拉伯文、 "用新華社文章訓練出來的" 簡體中文 parser。 請大家玩玩看中文 parser; 也把這篇文章介紹給英文/德文/阿拉伯文老師吧。
* * * 以下是 2010/11/27 初版未更改的舊資料 * * *
我在
mepis 8.5 底下, 內建的 java 是 openjdk-6-jre,
一開始無法顯示中文 (出現一堆方塊)。 呵呵既然要學英文,
就一不作二不休, 叫它別顯示中文吧: unset LANG
之後再執行 lexparser-gui.csh 所有的訊息就都變成英文,
一切問題都消失了 :-)
不行不行, 這樣是在躲避問題, 不是在解決問題。
請執行 xlsfonts | grep big5 看一下你的系統內有那些中文字型。
例如我的系統裡面有很多 -arphic-ar pl 開頭的文鼎字型, 所以隨便挑了一個:
-arphic-ar pl ukai tw-book-r-normal--0-0-0-0-p-0-big5-0
嗯, 我和你有相同的疑問: 「可是現在的 linux 都是 utf8 編碼呀?」
我猜系統應該會自動將 utf8 轉成 big5, 找出正確的字來顯示吧。 總之我這樣做, 是 ok 的:
進入 /usr/lib/jvm/java-6-openjdk/jre/lib 將 fontconfig.properties.src
複製成 fontconfig.properties 並且將裡面的
allfonts.chinese-big5=... 那一句改成:
allfonts.chinese-big5=-arphic-ar pl ukai tw-book-r-normal--*-*-*-*-p-*-big5-0
就是貼上字型名稱, 然後把中間五個 0 改成 *。 細節我也不熟悉;
有興趣的讀者詳見
How to install and use X-Windows fonts。
又, 或者請參考部落客 「佐」 的文章:
「OpenJDK的字體設定」。
[2011/2/4 補充] 我做的中文開機隨身碟
slax-cyut 底下收錄的 java 套件是 jre-6u11-i586-1pst.lzm;
而中文字型套件是 ttf-arphic-ukai.lzm。
上面的方法試半天, 失敗。 最後照著林老師貼的
「linux 下 java 1.5/1.6 的中文設定」 一文, 稍微修改步驟如下, 設定成功!
先用 grep ttf-arphic-ukai /proc/mounts
查出字型套件的根目錄在 /mnt/live/memory/images/ttf-arphic-ukai.lzm
然後 cd /mnt/live/memory/images/ttf-arphic-ukai.lzm ; du
查出 ttf 中文字型目錄在 usr/share/fonts/TTF 。
所以在 /usr/lib/java/lib/fonts/ 底下建一個 fallback
子目錄, 然後在這個新目錄底下:
ln -s /usr/share/fonts/TTF/fonts.* .
(注意最後面有一個句點, 代表將新建立的捷徑放在目前目錄底下。)
為什麼會找到這個東東呢? 因為我下學期要教 科技英文... 一定要用很科技的方法來教英文 (誤)。


剛剛根據新版的 Stanford Parser 2.0.4 重新改寫過這篇文章。
回覆刪除