 大人問小孩: 「全世界的玩具隨便你挑? 這怎麼可能?
如果我要的玩具只有一個, 正好又被別人借走了呢?」
大人問小孩: 「全世界的玩具隨便你挑? 這怎麼可能?
如果我要的玩具只有一個, 正好又被別人借走了呢?」是否曾經遇到過這樣的中文檔? 明知道它應該是採用 big5 編碼;
但用 vim 打開時, 卻看到一整片亂碼, 並且顯示錯誤訊息
「行 xx 有不正確的位元」 ("ILLEGAL BYTE in line xx")。
這是因為只要有任何一個字元編碼錯誤, vim 就會完全不知所措,
連其他正常的字也無法顯示。
這時可以打 :e ++enc=big5 強迫它以 big5 顯示。
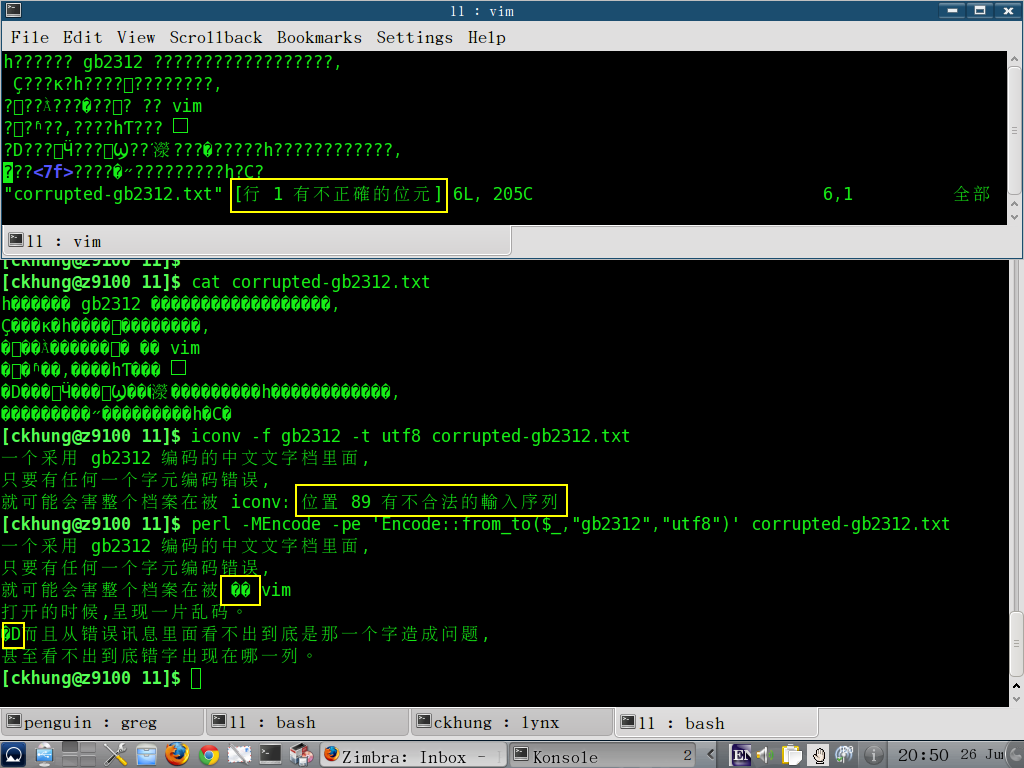
含有少數錯誤編碼的 gb2312 檔也可以用相同的方式處理: :e ++enc=gb2312。
我猜日文的 sjis/euc-jp 及韓文的 euc-kr 大概也類似。
若是 utf8 編碼的檔案就不會有這個問題 -- 即便裡面有幾個字是亂碼,
vim 還是會正確顯示其他字元。
 請下載
含有少數亂碼的 big5 編碼測試檔 或
含有少數亂碼的 gb2312 編碼測試檔。
請下載
含有少數亂碼的 big5 編碼測試檔 或
含有少數亂碼的 gb2312 編碼測試檔。
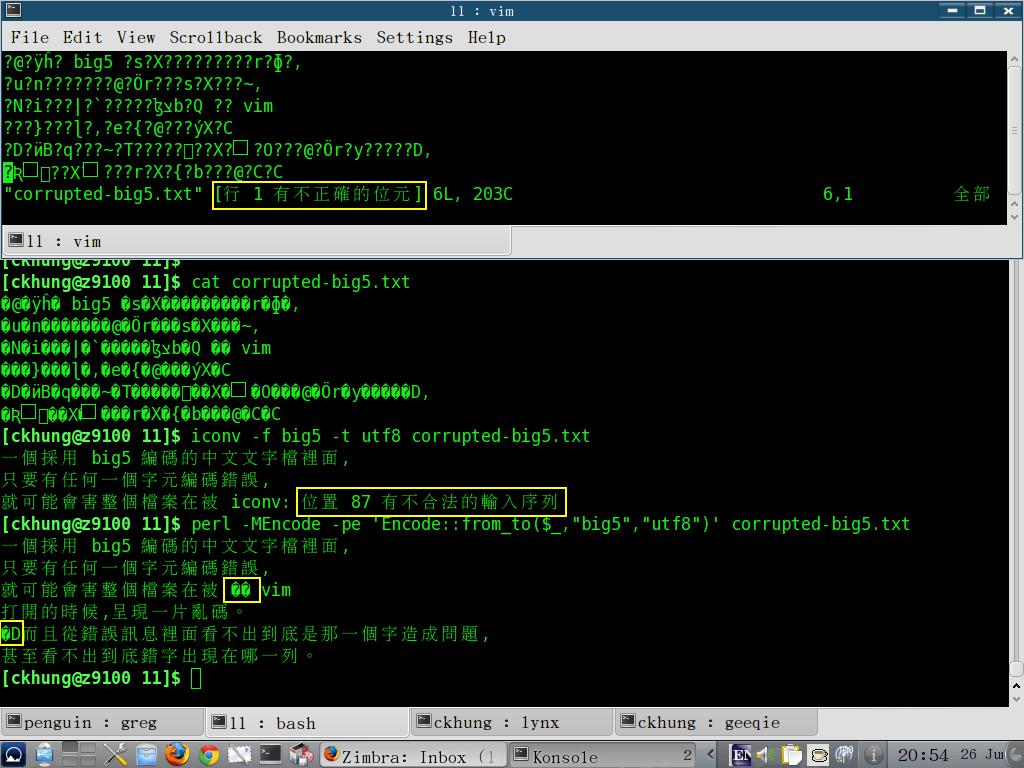
- 用 vim 打開, 看到的是整片亂碼。 而且, 不論真正的亂碼在哪一個位置, 永遠都顯示 「行 1 有不正確的位元」。 (順便一提, 其實應該翻成 「列 1 有不正確的位元組」 比較精確, 因為... 直行橫列 啊!)
- 用
iconv -f big5 -t utf8 corrupted-big5.txt將編碼轉成 utf8, 可以看到一部分的正確文字內容。 但是 iconv 很脆, 一遇到亂碼就停下來, 印出 「位置 87 有不合法的輸入序列」。 - 用
perl -MEncode -pe 'Encode::from_to($_,"big5","utf8")' corrupted-big5.txt將編碼轉成 utf8, 可以看到完整的內容, 以及少數幾個亂碼字元。
 所以如果只是要閱讀/檢視亂碼檔, 建議用 perl 轉碼。
嫌指令太長嗎? 可以在 ~/.bashrc 裡面加一句:
所以如果只是要閱讀/檢視亂碼檔, 建議用 perl 轉碼。
嫌指令太長嗎? 可以在 ~/.bashrc 裡面加一句: function b2u()
{ perl -MEncode -pe 'Encode::from_to($_,"big5","utf8")' $* ; }
以後就可以直接下 b2u corrupted-big5.txt 轉檔了。
(第一次剛設定好時, 必須先登出再登入之後才會生效。)
如果必須進 vim 編輯呢? 那麼進入 vim 之後,
就下 :e ++enc=big5 強迫它以 big5 顯示, 一切就正常了。
詳見
++enc。
不論有沒有強迫轉 big5, 一旦進入 vim, 原來的亂碼就會被
"矯正", 最後存檔時就會遺失資訊。
如果必須保留原來的亂碼, 那麼一進入 vim 就要立刻下:
:e ++bad=keep
強迫它在存檔時別矯正 "尚未刪除的亂碼"。
詳見
++bad。
我為了製作那兩個範例檔, 就是採用這個模式。
但是這個模式會讓所有中文字元改以十六進位顯示, 根本無法閱讀。
我是靠著插入其他檔案並且摸索著英文與半型標點符號才編出來的。
以上所有指令適用於 gb2312 簡體編碼。 請將指令當中所有的 big5 改成 gb2312 即可。 (但是我在 blogspot 的部落格好像被封鎖了是不是啊? 這段話大概只對新加坡和馬來西亞的讀者有用吧。)


沒有留言:
張貼留言
因為垃圾留言太多,現在改為審核後才發佈,請耐心等候一兩天。