 大人問小孩: 「全世界的玩具隨便你挑? 這怎麼可能?
如果我要的玩具只有一個, 正好又被別人借走了呢?」
大人問小孩: 「全世界的玩具隨便你挑? 這怎麼可能?
如果我要的玩具只有一個, 正好又被別人借走了呢?」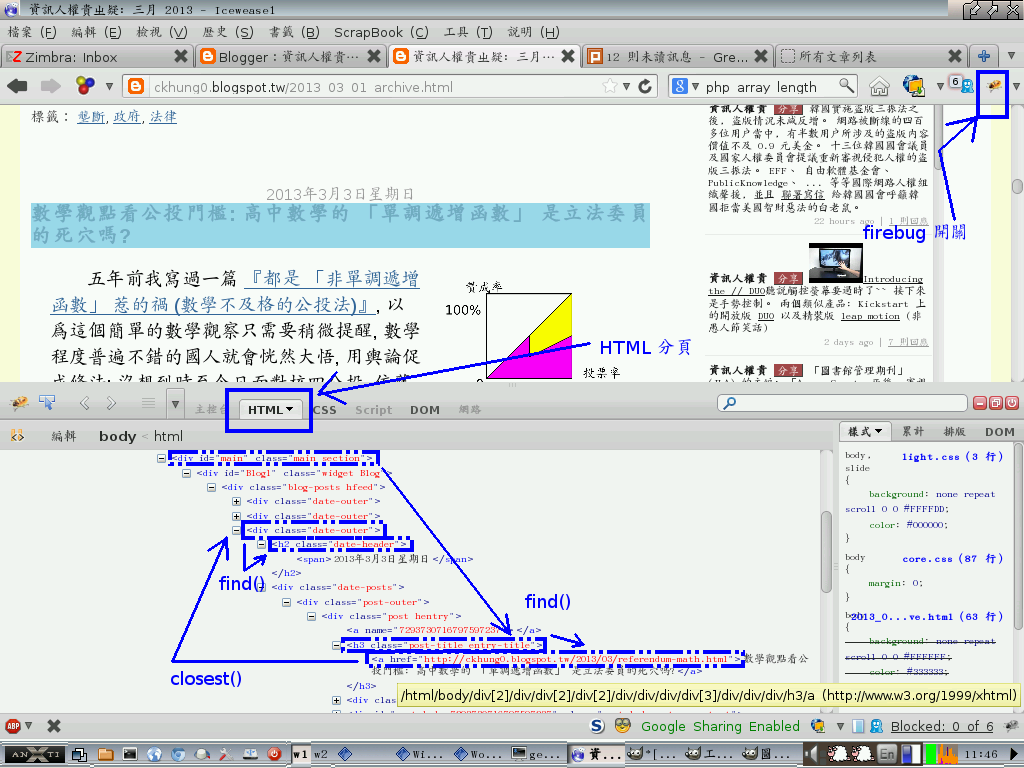 你會固定去某些部落格或新聞網站查看或下載文章/資料嗎?
希望把這些動作自動化 (省略手動點連結的動作) 批次化嗎?
或是你想寫一些小程式定期觀察某些網頁的某些欄位?
也許你需要學習 Document Object Model 跟 XPath?
總之, 如果你需要寫小程式抓取並分析網頁 (web scraping),
那就讓 firebug 跟 QueryPath (php 版的 jQuery) 來幫你吧。
本文介紹的是
你會固定去某些部落格或新聞網站查看或下載文章/資料嗎?
希望把這些動作自動化 (省略手動點連結的動作) 批次化嗎?
或是你想寫一些小程式定期觀察某些網頁的某些欄位?
也許你需要學習 Document Object Model 跟 XPath?
總之, 如果你需要寫小程式抓取並分析網頁 (web scraping),
那就讓 firebug 跟 QueryPath (php 版的 jQuery) 來幫你吧。
本文介紹的是 2.1.2 3.0.5 版。
[2016/9/8 改用新版 QueryPath 重新檢查過本文。
2.1.2 版要這樣引用
require_once 'QueryPath/QueryPath.php';
而 3.0.5 版要這樣引用
require_once 'QueryPath/qp.php';
本文只介紹很基本的功能, 所以除了以上及安裝方式不同之外,
沒有其他大修改。 ]
比方說, 我們可能想把 資訊人權貴ㄓ疑 這個部落格上面 2013 年 3 月份總共三篇文章砍下來, 並且把留言和固定的側邊欄砍掉, 只把文章主體內嵌到我們自己所設計的新框框裡面, 變成像 這樣 的映射頁面。 重要提醒! ==> (1) 大量砍站是不禮貌的行為 (2) 砍下來之後若再公開散佈, 可能會侵犯智慧財產權。 <== 重要提醒! 這個範例的站長以創用 cc 分享作品, 所以 (2) 不是問題 :-) 至於 (1) 的話, 因為這個範例正好是 google 開的站, 所以很強, 不怕你砍。 (什麼態度嘛~~) 總之等一下實驗的時候, 我們還是會盡量減少網路流量。
首先幫 firefox 安裝 firebug
套件, 並重新啟動 firefox。
瀏覽 「資訊人權貴ㄓ疑」, 在右側 「所有文章」 選取 「三月 2013 (3)」。
在瀏覽器的某個角落找到一隻小蟲圖樣打開 firebug,
下面就出現 firebug 的畫面。
在 firebug 的選單列上, 確認你目前選取的是 HTML 分頁。
下方就是目前所瀏覽的 HTML 頁面的
文件物件模型 (Document Object Model, 簡稱 DOM)
當你的滑鼠移到某個 element (元素) 上面時,
原始頁面上面對應的 element 就會用不同的顏色呈現。
請按 <body> 旁邊的 + 號,
把它打開, 再一路往下打開, 直到你可以移動滑鼠,
讓 3 月 3 日那篇 「數學觀點看公投門檻...」 的標題 (只有標題) 反藍為止。
跟隨著滑鼠位置而改變的, 還有旁邊淺黃底的一長串顯示目前 element 的字串,
也就是目前滑鼠底下這個 element 的 XPath。
(如果朝陽科大是一個 element, 那麼它的 XPath 就是
「臺中市霧峰區吉峰東路168號」 這個地址。)
<碎碎唸>我覺得以上這些是高中高職生應該學的電腦常識。 學習這類 「具有長遠價值」 的知識, 遠比每三年作廢一次的 Office 證照卓越 要有意義多了。 什麼時候才可以看到臺灣停止 「去網路化」 的資訊教育、 才可以看到教育部開始 把網路元素納入教育白皮書 呢? 什麼時候大家才會理解: 自由軟體的好處不僅僅是合法免費, 還有符合國際標準、 與網路趨勢一致呢?</碎碎唸>
接下來就用短短不到十列的 php 程式來截取網頁片段吧。
以前我都是用 perl 的 regexp 在爬網頁...
直到有一次突然發現超級好物
QueryPath, 馬上改變了我對 perl 數十年的忠貞情感!
呃, 其實現在我大部分時候還是用 perl 在做事啦;
不過要用 perl 的 regexp 分析網頁時, 最麻煩的是處理跨列問題。
雖然 perl 命令列上的 -000 選項跟 regexp 的 s
(single line) modifier 合起來也可以處理一部分的問題,
不過如果遇到比較複雜的問題 --
例如需要在在不同層次的結構之間跳來跳去找相關資料時
(見下面尋找文章刊出日期的例子) 改用 QueryPath 真的簡單太多了。
熟悉 javascript 的讀者馬上就會發現它是 php 版的 jQuery。
不熟 jQuery 也沒關係, 反正學會 QueryPath 之後, jQuery
的最基本重要功能也就會了 :-) 從 github 的 tag page
下載 2.1.2 3.0.5 版並解壓縮後, 請把整個 src/ 子目錄移到
/usr/share/php 底下, 改名為 QueryPath/ -- 總之最後要能看到
/usr/share/php/QueryPath/QueryPath.php/usr/share/php/QueryPath/qp.php 這個檔案。
再來請把要處理的頁面抓回來, 給它一個短名: wget -O 03.html
https://ckhung0.blogspot.tw/2013_03_01_archive.html
另外, 請把以下這段程式碼存成 genlisting.php
<?php
require_once 'QueryPath/qp.php';
$qp = htmlqp($argv[1]);
$x = $qp->find('#main h3.post-title')->html();
echo $x;
?>
然後就可以下: php genlisting.php 03.html
它會印出 "id 為 main 的那個元素底下的 post-title 類別的 h3 元素":
<h3 class="post-title entry-title">
<a href="https://ckhung0.blogspot.tw/2013/03/robot-laws.html">程式碼就是法律: 智慧財產權法 或 機器人三大法則?</a>
</h3>
作業: 請拿別的網頁練習, 用 firebug 觀察後, 試著修改上面程式的 標註部分, 看能不能抓到你要的元素。 [2016/9/8: 上面這個程式稍微寫得更通用一些, 就變成了: 網頁搜括小工具 extract.php 。]
上例當中, 其實符合條件的三個標題元素它都有抓到; 不過我們的程式沒寫好, 所以只印出第一個。 以下是改良版:
<?php
require_once 'QueryPath/qp.php';
$qp = htmlqp($argv[1]);
foreach ($qp->find("#main .post-title a") as $item) {
$url = $item->attr("href");
$title = $item->text();
$date = $item->closest(".date-outer")->find("h2.date-header")->text();
preg_match('#20(\d\d)年(\d+)月(\d+)日#s', $date, $matches);
list($year, $month, $day) = array_slice($matches, 1);
echo sprintf("sleep 3; wget -O $year%02d%02d.html $url\n# [$title]\n", $month, $day);
}
?>
在使用 QueryPath 的時候, 除了最常用的 find()
可以拿來 「向裡面搜尋」 之外, 還有 end()
可以 「退回到上一次 find() 的地方」 以及 closest()
可以 「向外搜尋」。 抓到一個元素之後,
我最常做的事就是用 html() 或 text()
把它轉成普通字串 (而不再是 QueryPath 的物件) 並且用 regexp 加工處理。
[2018/4/21] 在 QueryPath 裡面最重要的類別就是 DOMQuery, 也就是 htmlqp() 所產生、 後續一路上所有查詢所傳回的物件所屬類別。 但也可以用 toArray() 或 get() 把它轉換成 php 的內建的 DOMElement 類別 的陣列。 當然, 如果想要再對每個元素呼叫 text() 及 html() 等等好用的函數, 就必須再用 htmlqp() 把每個元素轉換回 DOMQuery 。
事實上, 上面這個改良版可以拿來產生一個 shell script:
php genlisting.php 03.html > get-posts.sh
用編輯器檢查 get-posts.sh 的內容無誤後,
就可以拿它來把這個月份的所有文章整批下載回來:
source get-posts.sh
這裡面的 sleep 3 是為了禮貌, 在兩次下載之間加一點延遲,
避免造成你喜愛的網站仿佛遭到 DOS 連珠炮般的攻擊。
法學教授 James Grimmelmann 替
Aaron Swartz 抱屈, 在
My Career as a Bulk Downloader (「我的大量下載職業生涯」)
一文當中也提及大量下載時應注意的這個禮貌。
[2016/10/11] 如果 html 資料檔沒有標頭宣告 charset=UTF-8, 那麼中文會變亂碼。 此時需要先在資料檔前面加上 (內含此句的) <head>、 外面包上一層 <html>, 然後才可以丟給 htmlqp 處理。 詳見 網頁搜括小工具: extract.php 以及 QueryPath中文乱码问题。
我會找到 QueryPath, 除了因為上述想要映射自己部落格的需求之外, 還有另一個原因。 我那支 「不太智慧手機」 只要遇到太大的 html 檔常常就悲劇了 orz... 但是我又很需要把一些部落格文章放在手機記憶卡上面, 每當排隊/等餐/等老婆血拼的時候, 就可以拿出來離線閱覽。 如果你想到 QueryPath 更實用、 更普遍的應用情境, 請分享一下吧!


有點複雜, 不過很值得參考, 謝謝囉!
回覆刪除正常人都是直接換手機。
回覆刪除@羅邦迪: 已加上黃底強調顯示, 若想自己實驗, 只要修改這邊就可囉!
回覆刪除@匿名: 真的, 我老婆也這麼覺得。 可是我為了延後製造電子垃圾, 一直抗拒身旁人的勸敗 :-)
QueryPath愛用者,在遇到QueryPath之前..我都是用正規表示式來去掉不需要的標籤來取得我需要的內容....雖然現在還是有用到正規表示式...但是沒有像之前用的那麼兇~~~^^
回覆刪除貴哥可以參考 beautiful soup, 用 python 的.
回覆刪除jQuery 也能做到類似的事吧?
回覆刪除