 大人問小孩: 「全世界的玩具隨便你挑? 這怎麼可能?
如果我要的玩具只有一個, 正好又被別人借走了呢?」
大人問小孩: 「全世界的玩具隨便你挑? 這怎麼可能?
如果我要的玩具只有一個, 正好又被別人借走了呢?」我經常 用網路時光機備份歷史。 但是遇到有 javascript 的頁面, wayback machine 有時會失敗。 又例如噗浪的討論串如果太長, 「較早的留言」 可能需要手動點才會顯示。 這時只好手動備份。 今天就拿 烏克蘭拉攏中國討論串 來作例子, 示範如何手動備份網路時光機備不下來的網頁。
[2024/3/22] 最近才知道: 如果想備份的是噗浪的頁面, 可以用 「讀噗」。 到 這裡 直接輸入某噗的網址或代號, 也可查看該對話串的鏡射, 然後就可以再用網路時光機備份這個鏡射頁面。 不過好像還是會有「太長的對話藏在 javascript 後面,以致無法完整備份」的問題。
首先備份文字。 在 firefox 裡面按 ctrl-shift-i, 下方出現除錯窗格。 確認所有的留言都已展開之後, 點窗格左上角的 「箭頭加方框」 進入選擇元件的模式。 移動滑鼠, 會看到網頁上不同的區域亮起來, 同時下方對應的 html 段落也會跟著稍微變亮。 把滑鼠移到想要備份的文字外框, 點下去, 就等同於選取了下方對應的 html 段落。 在那個段落上面按滑鼠右鍵、 選複製、 內部 html, 就可以把它的內容貼到 geany 或其他文字編輯器上面。 再按一次 ctrl-shift-i, 下方除錯窗格就收掉了。 這段 html 檔可以嵌到你的部落格或網頁裡面去, 雖然長相會跟原來的不太一樣, 而且圖片可能會消失, 但保留文字版本, 將來要搜尋比較方便。 如果想把它變成一張獨立的網頁, 記得要加上 <meta charset="utf-8">:
<head>
...
<meta charset="utf-8">
...
</head>
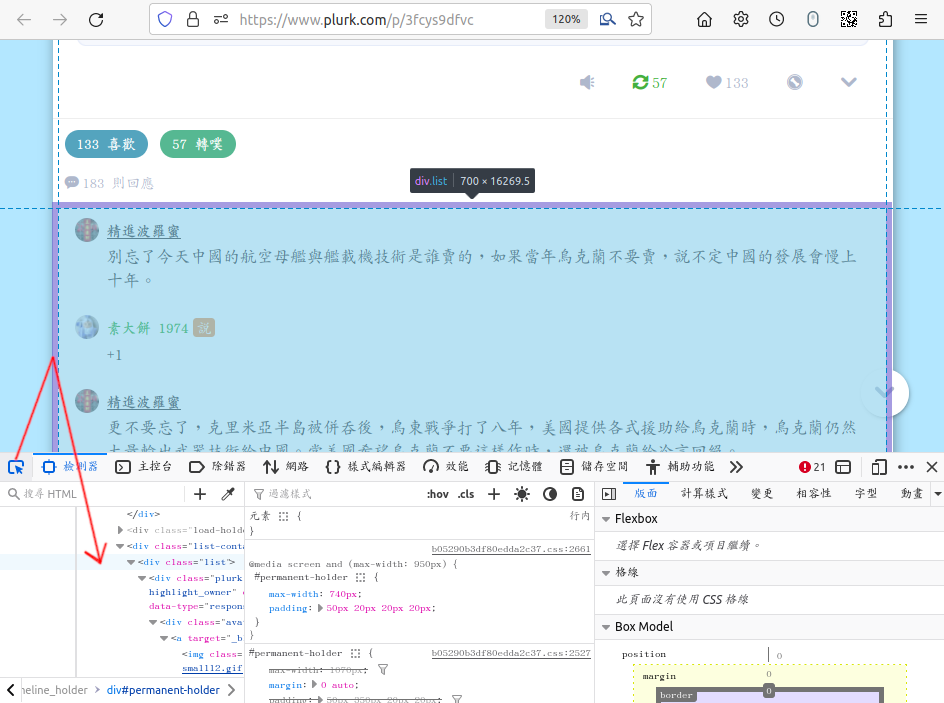
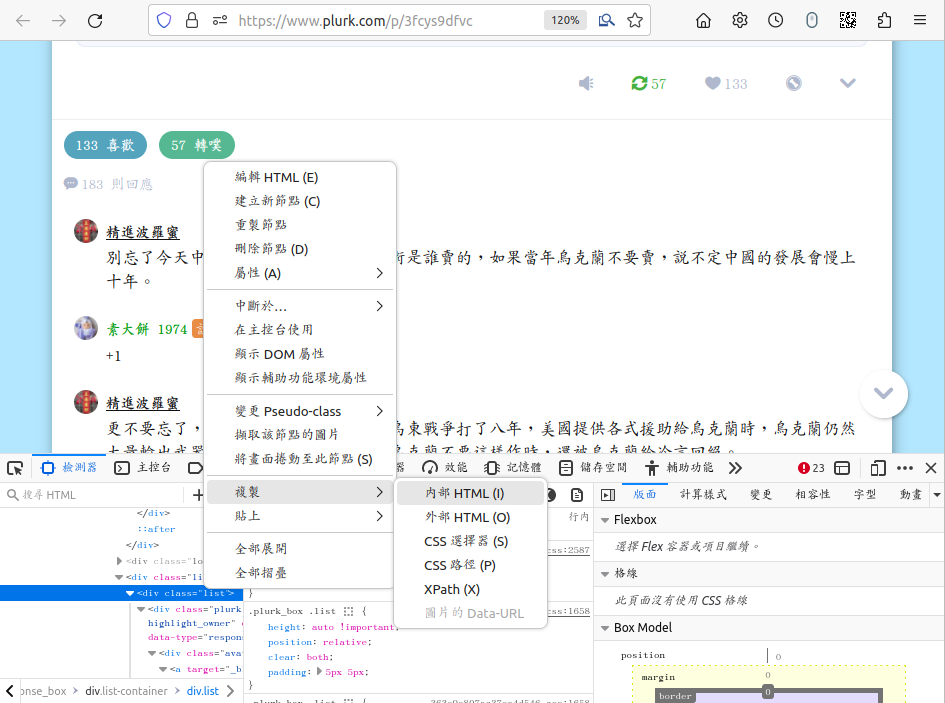
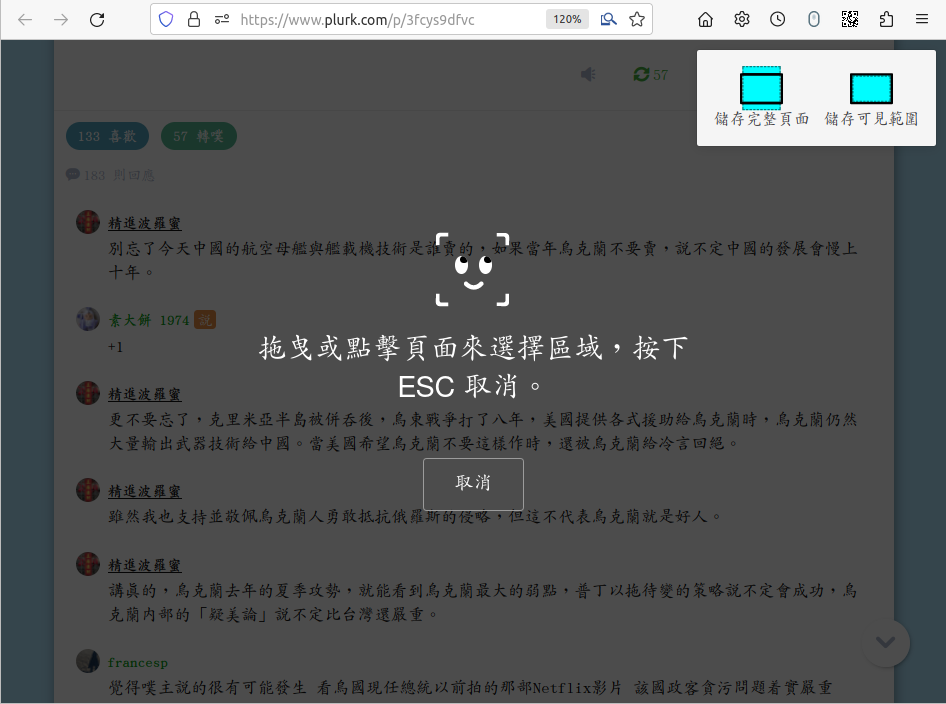
文字備份的功能性比較高; 但是大家可能很難接受排版走樣的備份。 所以再次確認所有的留言都已展開之後, 接下來按 ctrl-shift-s 進入 「截圖備份」 模式。 點選 「儲存完整頁面」, 或是點選一小塊留言, 再用高亮度框四週的控制點與邊框調整想要備份的部分, 最後存檔, 假設檔名為 full.png。 這是一張超級長的截圖, 用 identify full.png 查看, 結果竟然沒有輸出?! 再用 gimp 打開, 我看到的大小是 945x20405。 (當初我選擇略過噗首,只存留言。)
這種大小當然要切開才能閱讀啊!
切圖就用 imagemagick 套件的 convert 指令囉。
先測試一下: convert -crop 900x1200+20+0 full.png p00.png
出現 "no images defined" 錯誤。
找到 這個問答,
原來是圖片大小超過 imagemagick 的極限了。
編輯 /etc/ImageMagick-6/policy.xml , 找到這一列:
<policy domain="resource" name="height" value="16KP"/>
把 16KP 改成 25KP (垂直方向上限兩萬五千 pixels),
identify 指令跟 convert 指令就可以正常運作了。
切圖的時候, 希望前後兩張圖略有重疊。
找到 這個問答,
可是看不懂, 也搜尋不到相關指令的教學。
算了, 自己用 perl 產生指令比較快。
算了一下, 如果每張圖的高度是 1200 pixels, 上下兩張圖重疊 40 pixels,
ceil(20405/(1200-40)) = 18 張圖可以覆蓋全部。 於是這樣下指令:
perl -e 'for $i (0..18) { printf("%02d %d\n", $i, $i*1160); }' | perl -pe 's#(\d+)\s+(\d+)#convert full.png -crop 900x1200+22+$2 +repage p$1.jpg#'
這會產生 18 句 convert 指令。
看起來如果正確, 就把它 pipe 給 bash 執行, 產生 18 個 p??.jpg。
最後把圖、文兩種備份的成果都貼到部落格去, 得到:
社群媒體抓共匪。
網路歷史學家貴哥拜託大家要經常幫忙備份重要的證據與歷史文物嘿~


沒有留言:
張貼留言
因為垃圾留言太多,現在改為審核後才發佈,請耐心等候一兩天。