 大人問小孩: 「全世界的玩具隨便你挑? 這怎麼可能?
如果我要的玩具只有一個, 正好又被別人借走了呢?」
大人問小孩: 「全世界的玩具隨便你挑? 這怎麼可能?
如果我要的玩具只有一個, 正好又被別人借走了呢?」在臉書上看到一張圖: 比較一些國家的薪資中位數 vs 電價。 忍不住想用 scatplot 重畫一次。 我詢問資料出處, 可惜原繪圖者沒回答。 只搜尋到 "World Population Review" 的這兩頁: Median Income by Country 跟 Cost of Electricity by Country。 點表格右上方的 "csv" 即可索取、 從 email 收到 inc.csv 跟 ec.csv 這兩個 csv 檔。 用我的小程式 country-encode.py 幫兩檔各自加上 iso 三碼國碼、 依國碼排序、 用 join 合併、 用 libreoffice calc 打開、 手動整理一些小地方, 最後得到 inc-ec.csv。 再搭配 inc-ec.json 設定檔, 畫出 「電價 vs 收入中位數」 互動氣泡圖。 <== 點我!
2024年4月20日 星期六
2024年4月11日 星期四
設定輕巧視窗環境 icewm
先前 在 eee pc 上面安裝 debian 時, 需要找一個輕量級的視窗管理員, 其中最關鍵的參數是記憶體用量。 這篇文章 比較十幾個視窗管理員, 看到 icewm 時就毫不猶豫地選它了, 因為它是我二十幾年的老朋友。 本文描述的是 debian 12.5 (bookworm) 上的 icewm 3.3.1。
2024年3月25日 星期一
十六年前的懷舊電腦 eee pc 上跑 AI 年代的作業系統
 哈哈, 2008 年出廠的 32 bit
eee pc 1001px
如果沒有用雲端服務, 當然跑不動 AI 程式啊!
我的意思是: 2024 年的現代 (AI 年代), 只要選擇正確的作業系統,
你的舊電腦照樣可以很秋!
哈哈, 2008 年出廠的 32 bit
eee pc 1001px
如果沒有用雲端服務, 當然跑不動 AI 程式啊!
我的意思是: 2024 年的現代 (AI 年代), 只要選擇正確的作業系統,
你的舊電腦照樣可以很秋!
2024年3月24日 星期日
安裝新版 debian 重點筆記
2024年3月23日 星期六
deb 轉檔: 新版 zst 壓縮改成舊版 xz 壓縮
按照 refind 作者的安裝教學文
下載了 refind 0.14.0.2 並且試著安裝:
dpkg -i refind_0.14.0.2-1_amd64.deb,
結果出現錯誤訊息:
"archive 'refind_0.14.0.2-1_amd64.deb' uses unknown compression
for member 'control.tar.zst', giving up"。
原來是因為我的系統太舊 (linux mint debian edition 5, "Elsie"),
不認得新的 .deb 檔裡面的壓縮格式。
找到 這個問答,
已有網友寫了一個小的 script:
#!/bin/bash
DEBPACKAGE="${1%.deb}"
[[ -z "$1" ]] && echo "Usage: $0 some_package.deb" && exit 1
set -e
ar x $DEBPACKAGE.deb
zstd -d < control.tar.zst | xz > control.tar.xz
zstd -d < data.tar.zst | xz > data.tar.xz
ar -m -c -a sdsd "$DEBPACKAGE"_repacked.deb debian-binary control.tar.xz data.tar.xz
rm debian-binary control.tar.xz data.tar.xz control.tar.zst data.tar.zst
把它存檔, 隨便取個名字, 例如 zst2xz-deb、
改成可執行、 並且安裝 zstd 套件, 然後:
./zst2xz-deb refind_0.14.0.2-1_amd64.deb
就會產生 (採用較舊、相容性較好的 xz 演算法所壓縮的)
refind_0.14.0.2-1_amd64_repacked.deb
之後就可以用 dpkg -i 安裝了。
2024年3月22日 星期五
查看、修改與保護 uefi 裡面的 nvram/變數
安裝最新的 0.14 版 refind 套件時, 畫面閃過 "Creating new NVRAM entry" 的訊息, 下次開機時發現它竟然直接攻佔了我電腦的開機選單! 而且它不是安裝在某顆硬碟的 MBR, 而是裝在更上游的 UEFI NVRAM, 也就是主機板的韌體上。 還好 linux 程式都很有分寸的 , 只是多加了一層選單, 從那裡仍舊可以看到並選取我原來的選單。 (而不是像三十幾年前, 沒品的微軟直接廢了我原本的 OS/2 多重開機選單。) 總之這促使我開始爬文認識 UEFI 韌體管理/EFI variables。 以下測試不必進入 UEFI, 在 linux 命令列底下就可以進行。
2024年2月18日 星期日
遠端桌面連線軟體 VNC 也可以當成電子白板或廣播教學軟體來用, 2024 版
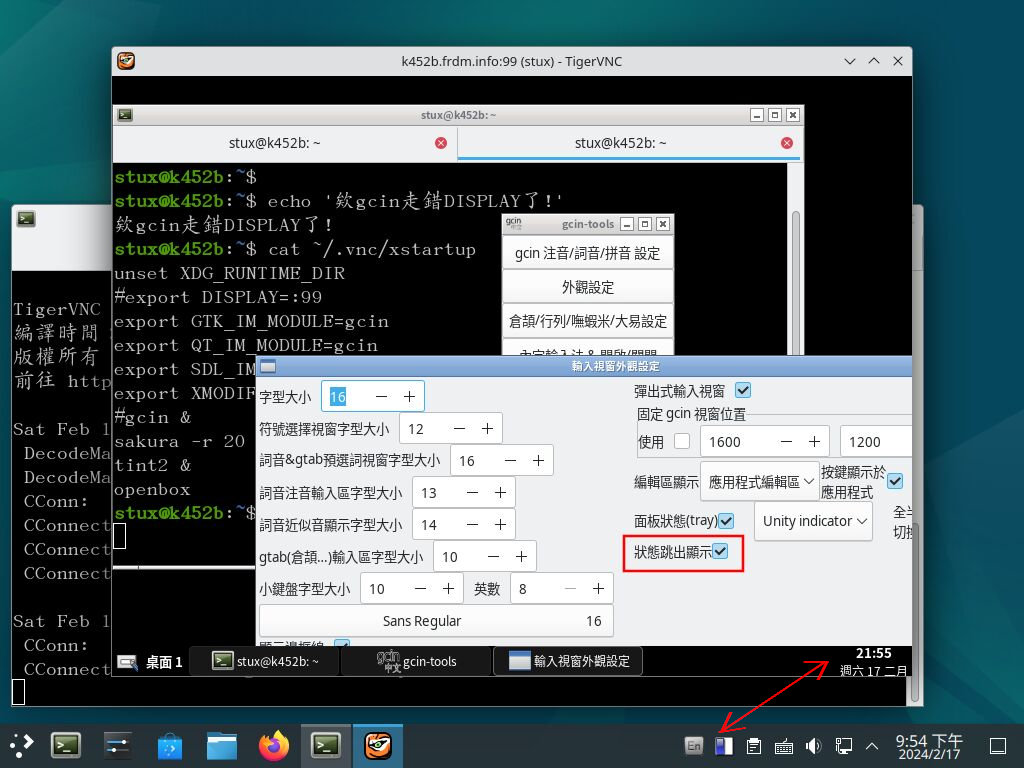 這幾天正在 用虛擬機安裝 debian 12.5 "bookworm" 。
今天先把 bookworm 上面安裝 tigervnc 及中文輸入法時遇到的問題記錄下來。
這幾天正在 用虛擬機安裝 debian 12.5 "bookworm" 。
今天先把 bookworm 上面安裝 tigervnc 及中文輸入法時遇到的問題記錄下來。
2024年2月5日 星期一
播放 midi 音樂, 馬虎版
今天終於學會播放 midi 音樂! 暫時先不管播放品質了, 可以盡快試車比較重要。 我的測試環境是 LMDE 5 (Elsie); 主要參考 archlinux 的教學文; 我猜大部分 debian 系列應該也都可以。
2024年2月3日 星期六
手動製作一長串討論的網頁圖文備份
我經常 用網路時光機備份歷史。 但是遇到有 javascript 的頁面, wayback machine 有時會失敗。 又例如噗浪的討論串如果太長, 「較早的留言」 可能需要手動點才會顯示。 這時只好手動備份。 今天就拿 烏克蘭拉攏中國討論串 來作例子, 示範如何手動備份網路時光機備不下來的網頁。
[2024/3/22] 最近才知道: 如果想備份的是噗浪的頁面, 可以用 「讀噗」。 到 這裡 直接輸入某噗的網址或代號, 也可查看該對話串的鏡射, 然後就可以再用網路時光機備份這個鏡射頁面。 不過好像還是會有「太長的對話藏在 javascript 後面,以致無法完整備份」的問題。
2024年1月30日 星期二
vosk: 影片/音檔聽寫機
我比較喜歡閱讀; 不太喜歡看影片/聽podcast。 找到 summarize.tech 這個網站不錯, 餵它一部英文 youtube 影片連結, 就幫你產生文字摘要。 但是它好像只吃有附字幕檔的影片。 那如果是其他語言呢? 我試了 一部自動產生字幕的西班牙文影片, 它會產生英文的文字摘要。 那如果是用 video downloadhelp 抓回來的影片呢? 如果想離線使用呢? 那就安裝 vosk, 在自己的電腦上離線產生各種語言的字幕檔吧!
2024年1月24日 星期三
2024年1月21日 星期日
自學 SQL 語法? sqlite 幫你閃電入門!
[我失憶了嗎? 2022/4 早就寫過一篇差不多的: SQL 自學起手式]
關於資料庫這門課, 我一直覺得最值得初學者花時間的有趣地方是
ER model 跟 select 指令的各種花式變化。
也一直覺得很多同學很可憐, 被帶著從 Oracle
或 MS SQL 的管理開始學起,
光是設定帳號密碼, 熱情跟好奇心就被澆了一些冷水。
就連自由軟體 PostgreSQL 或 mariaDB 我也覺得並不適合新手。
最適合新手的, 是不必帳號密碼、 沒有複雜管理系統、
直接以一個檔案儲存一個資料庫的 sqlite!
在 debian 系列上: apt install sqlite3
把它安裝起來吧!
訂閱:
文章 (Atom)

