 大人問小孩: 「全世界的玩具隨便你挑? 這怎麼可能?
如果我要的玩具只有一個, 正好又被別人借走了呢?」
大人問小孩: 「全世界的玩具隨便你挑? 這怎麼可能?
如果我要的玩具只有一個, 正好又被別人借走了呢?」玩資料視覺化, 經常需要從網頁上下載表格, 再轉成 csv。
以前就曾搜尋到
sebsauvage.net 上面的 html2csv.py,
後來忘記了; 最近又重新發現一次。
很簡單: python2 html2csv.py abc.html 它會把 abc.html
裡面的所有表格串在一起, 產生一個 abc.csv 。
如果有合併列或合併欄等等比較複雜的狀況, 還是需要後續處理,
但至少比自己寫 regexp 簡單多了。 全文完。
 喂~ 這樣就結束? 這篇未免太 ㄌㄢˋ ㄩˊ ㄔㄨㄥ ㄕㄨˋ 了吧!
[現在有同音異字的成語太多了, 我都不知道國字該怎麼寫才對...]
至少應該要交代一下如何取得 html 啊。 如果是大量的靜態網頁,
可以用 wget 或 lynx -dump 或 curl 取得。
有可能需要
設定 user agent 才不會被網站拒絕。
如果是 javascript 所動態產生的、 上述指令無法取得的網頁呢?
如果頁面數量很多, 那就考慮用
puppeteer。 如果只是單一或少數的 [js 動態產生的] 頁面,
那就手動另存新檔就好。
可是有一些 js 頁面需要你點幾個地方之後, 才會動態填值進表格。
這時 firefox 的 console 就很好用了 --
即使不是 js 程式設計師也值得學一下。
喂~ 這樣就結束? 這篇未免太 ㄌㄢˋ ㄩˊ ㄔㄨㄥ ㄕㄨˋ 了吧!
[現在有同音異字的成語太多了, 我都不知道國字該怎麼寫才對...]
至少應該要交代一下如何取得 html 啊。 如果是大量的靜態網頁,
可以用 wget 或 lynx -dump 或 curl 取得。
有可能需要
設定 user agent 才不會被網站拒絕。
如果是 javascript 所動態產生的、 上述指令無法取得的網頁呢?
如果頁面數量很多, 那就考慮用
puppeteer。 如果只是單一或少數的 [js 動態產生的] 頁面,
那就手動另存新檔就好。
可是有一些 js 頁面需要你點幾個地方之後, 才會動態填值進表格。
這時 firefox 的 console 就很好用了 --
即使不是 js 程式設計師也值得學一下。
 先前買股票都是每季到
goodinfo 去逐檔下載財報摘要。
這次發現
鉅亨網的財報摘要
把所有上市櫃股票資料放在同一頁, 超方便的。
以下用 firefox 操作。
先前買股票都是每季到
goodinfo 去逐檔下載財報摘要。
這次發現
鉅亨網的財報摘要
把所有上市櫃股票資料放在同一頁, 超方便的。
以下用 firefox 操作。
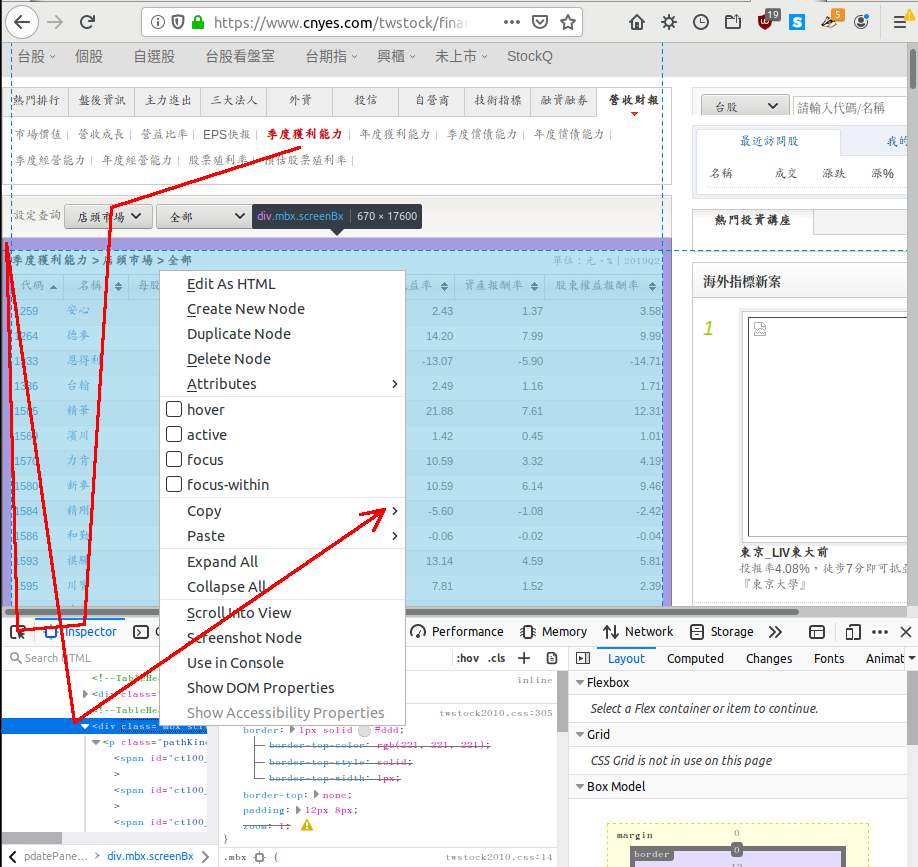
- 點選你想看的表格, 例如 「季度獲利能力」。
- 點選 「設定查詢」 的 「店頭市場」, 表格內容變成所有上櫃股票。
- 按 ctrl-shift-i 叫出火狐的 「開發者工具」。
- 點一下 「inspector」、 再點一下它左邊的 「頁面元素選取工具」。 現在移動遊標時, 頁面上的各區塊會跟著亮起來。
- 移到有興趣的表格邊緣, 點一下, 下方對應的 html 原始碼也會亮起來。
- 遊標移回下方亮起來的那一列 (可能是 table 本身, 但更可能是外圍的 div, 無所謂), 按右鍵叫出選單。
- 點一下選單的 「copy」 裡面的 「inner html」, 複製表格的 html 原始碼。
- 打開 geany 或 vim 等等任何一個文字編輯器、 貼上、 存成 otc.html。
python2 html2csv.py otc.html產生 otc.csv。- 「設定查詢」 改選 「集中市場」, 上面幾步再重複一次, 產生 sem.csv。
- 把上市、 上櫃兩個 csv 檔合併、 排序、
分隔欄位用的逗點暫時改成分號、 其他 (數字裡面的) 逗點刪掉、
雙引號跟空格也同時刪掉、 分隔欄位用的分號再改回逗點,
最後產生 19Q2.csv:
sort sem.csv otc.csv | perl -pe 's/","/";"/g; s/[," ]//g; s/;/,/g ' > 19Q2.csv
像這種需要互動 ("點選 「設定查詢」 的 「店頭市場」") 的狀況, 需要自己寫 puppeteer 程式, 無法直接套用那一篇的 pptscraper.js 指令, 所以如果頁面數量不多, 還是手動下載比較簡單。 另外, 有時遇到頁面表格太多、 html 層層標籤太複雜, 導致直接使用 html2csv 時失敗, 那也可以用這招, 手動把表格複製出來, 再用 html2csv 轉檔, 非常方便。
* * * * *
其實財報我也只會看 eps、 roe、 bps 這幾個數字。 鉅亨網的財報摘要比 goodinfo 早出來又好下載, 雖然只有 eps 跟 roe, 搭配著三個月前從 goodinfo 下載的上一季 bps, 已經可以拿來大約估算 次年配息 跟 GVI 等等數值。 不過幾天後 goodinfo 的資料下載完畢後, 才發現跟鉅亨網的資料不太一樣。 跟其他網站再對照一下, 感覺鉅亨網的好像有一些誤差。 好吧, 這個頁面沒有真的幫我發大財, 不過至少讓我學到一招了~


沒有留言:
張貼留言
因為垃圾留言太多,現在改為審核後才發佈,請耐心等候一兩天。